¿Se está impidiendo a los bots de Inteligencia Artificial acceder al contenido?
Publicado por Lino Uruñuela el miércoles 26 de febrero de 2025 (2025-02-26)
índice
El otro día mostré cómo podíamos obtener 72 millones de robots.txt, y le cogí vicio, así que me puse a procesar otras fechas pasadas, concretamente
- 2022 - Agosto - Crawl Archive (CC-MAIN-2022-33)
- 2023 - Septiembre / Octubre - Crawl Archive (CC-MAIN-2023-40)
- 2024 Febrero / Marzo - Crawl Archive (CC-MAIN-2024-10)
- 2024 Octubre - Crawl Archive (CC-MAIN-2024-46)
- 2025 Enero - Crawl Archive (CC-MAIN-2025-05)
- 2025 Febrero - Crawl Archive (CC-MAIN-2025-08)
Con el objetivo de comprobar cómo está reaccionando la industria ante la llegada de la IA y el debate abierto sobre el uso de contenido por parte de sus bots para alimentar el cerebro de los grandes modelos de leguaje me propuese analizar si con el paso del tiempo hay un aumento considerable en las restricciones que se le ponen a estos rastreados a la hora de acceder al contenido, con este objetivo en mente he analizado diferentes rastreos de CommonCrawl para ver esta evolución
Debemos saber que los robots.txt obtenidos en los rastreos de CommonCrawl varían de un mes a otro, no todos los dominios que se procesaron en enero han sido procesados en febrero.
La misma URL de un robots.txt puede haber sido rastreada por CommonCrawl una, varias o muchas veces al mes, esto lo he tenido en cuenta a la hora de calcular en cuantos dominios aparece cada User Agent. Si un robots.txt de un dominio concreto contiene por ejemplo 'Googlebot', aunque el robots.txt de este dominio haya sido rastreadp cien millones de veces solo contará una, ya que queremos saber en cuántos dominios diferentes aparece.
Puede haber más de un robots.txt por cada subdominio, por ejemplo la versión http y https del mismo hostname, http://www.midominio.dev/robots.txt y también https://www.midominio.dev/robots.txt, en este caso yo los cuento como el mismo aunque realmente son dos urls diferentes.
Para un mismo dominio puede haber más de un subdominios (hostname), de hecho hay dominios que tienen miles de subdominios, para muestra un botón....
Datos de los dominios con más subdominios
| Dominio | Subdominios |
|---|---|
| weebly.com | 105.117 |
| medium.com | 61.647 |
| list-manage.com | 45.937 |
| substack.com | 39.863 |
| fc2.com | 30.118 |
| bigcartel.com | 28.968 |
| teachable.com | 23.107 |
| amazonaws.com | 18.641 |
| mystrikingly.com | 16.583 |
| deviantart.com | 15.430 |
| peatix.com | 14.954 |
También debemos saber que los datos mostrados aquí son datos de robots.txt sin errores, porque no os imagináis lo que la gente es capaz de añadir a un robots.txt... eso lo dejaré para otro día, donde mostraré algunas "perlas"...
En total he obtenido y procesado más de 416.349.385 robots.txt diferentes, podemos ver en esta gráfica el número de dominios, subdominios y robots.txt procesados cada mes
Gráfica y tabla con los datos extraidos de rastreos de Common Crawl en 5 fechas diferentes
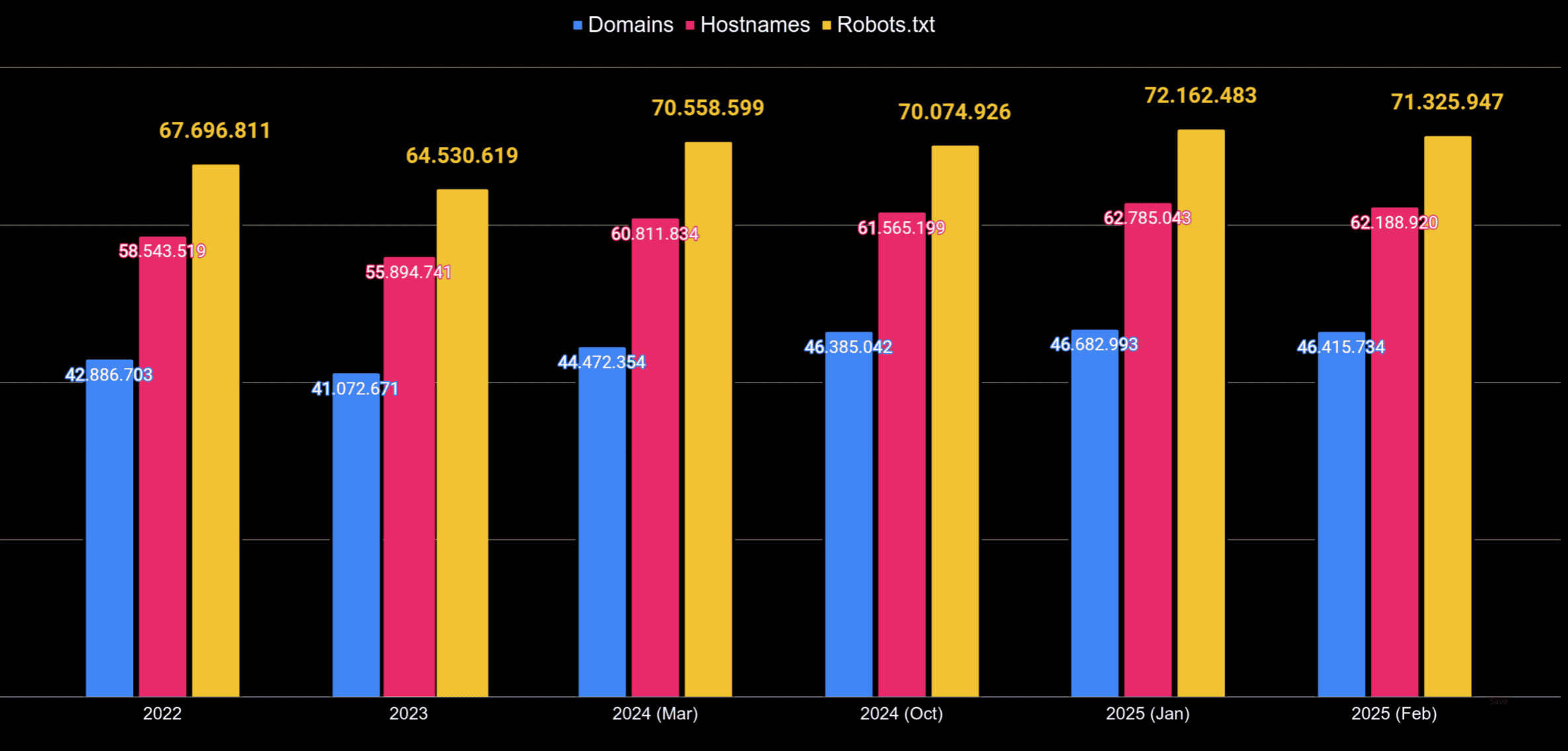
| Año | totales | Dominios | Hostnames | robots.txt | UserAgents |
|---|---|---|---|---|---|
| 2025 (Febrero) | 185.089.326 | 46.415.734 | 62.188.920 | 71.325.947 | 8.186 |
| 2025 (Enero) | 190.017.148 | 46.682.993 | 62.785.043 | 72.162.483 | 8.212 |
| 2024 (Octubre) | 179.744.091 | 46.385.042 | 61.565.199 | 70.074.926 | 7.777 |
| 2024 (Marzo) | 189.637.559 | 44.472.354 | 60.811.834 | 70.558.599 | 7.747 |
| 2023 | 180.799.446 | 41.072.671 | 55.894.741 | 64.530.619 | 7.486 |
| 2022 | 179.883.709 | 42.886.703 | 58.543.519 | 67.696.811 | 7.415 |
Bots "habituales"
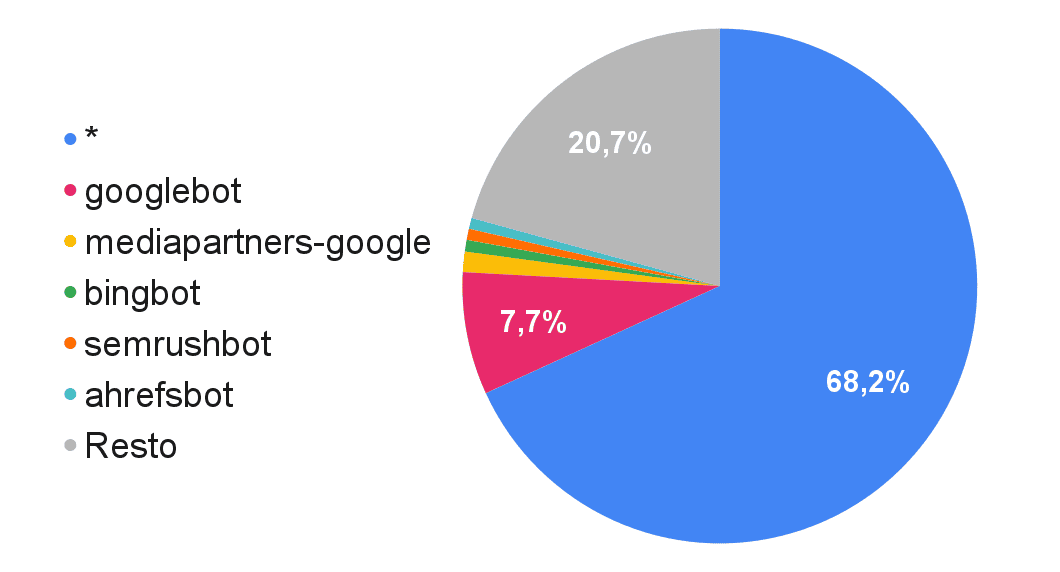
Cualquiera que haya analizado ocasionalmente logs del servidor estará acostumbrado a estos User Agents, ya que como vemos en esta tabla son los más asiduos.
La columna 'Robots.txt en los que aparece' son el número de URLs únicas de robots.txt en los que se ha encontrado cada uno de los User Agent, así por ejemplo '*' aparece en más de treinta y tres millones de robots.txt, Googlebot en casi cuatro millones de robots.txt, mientras que semrushbot lo hace en trescientos cuarenta mil.
| 2025 febrero | ||
| BOTS | Robots.txt en los que aparece | % sobre el total |
|---|---|---|
| * | 33.133.989 | 68,16% |
| googlebot | 3.742.816 | 7,70% |
| mediapartners-google | 620.388 | 1,28% |
| bingbot | 356.642 | 0,73% |
| semrushbot | 340.516 | 0,70% |
| ahrefsbot | 332.491 | 0,68% |
| dotbot | 218.890 | 0,45% |
| blexbot | 213.099 | 0,44% |
| yandex | 211.392 | 0,43% |
| msnbot | 183.559 | 0,38% |
Dentro de los bots "habituales" el primer puesto es el asterisco '*', regla que hace mención a cualquier bot, sin distinción. Googlebot es con diferenecia el bot más nombrado en los robots.txt.
En la siguiente imagen se ve la proporción de "presencia" para los principales bots habituales.
¿Cuáles son los User Agent que identifican a los bots usados por la Inteligencia Artificial?
De todos los User Agents encontrados cogí los más populares, se los pasé a chatGPT, Gemini, etc para obtener una lista de aquellos que son propios de rastreadores identificados para el uso de la IA. La lista irá creciendo poco a poco, de momento creo que con estos nos vale.
Esta es la lista de los User Agent identificados como bots de IA
gptbot, claudebot, google-extended, chatgpt-user, anthropic-ai, cohere-ai, perplexitybot, oai-searchbot, perplexity-ai, anthropicbot, bard, openai-api, deepseekbot, huggingfacebot, ai21bot, ai2bot, airesearchbot, anthropic-crawler, ccbot/2.0, claude-webbo, cohere-crawler, coherebot, google-generative-ai-crawler, groqbot, img2dataset, llama-control, meta ai bot, midjourneybot, omgilibot/1.0, stabilitybot, petalbot, aihitbot, duplexweb-google, mlbot, bytespider, pixray-seeker, aipbot, aibot, youbot
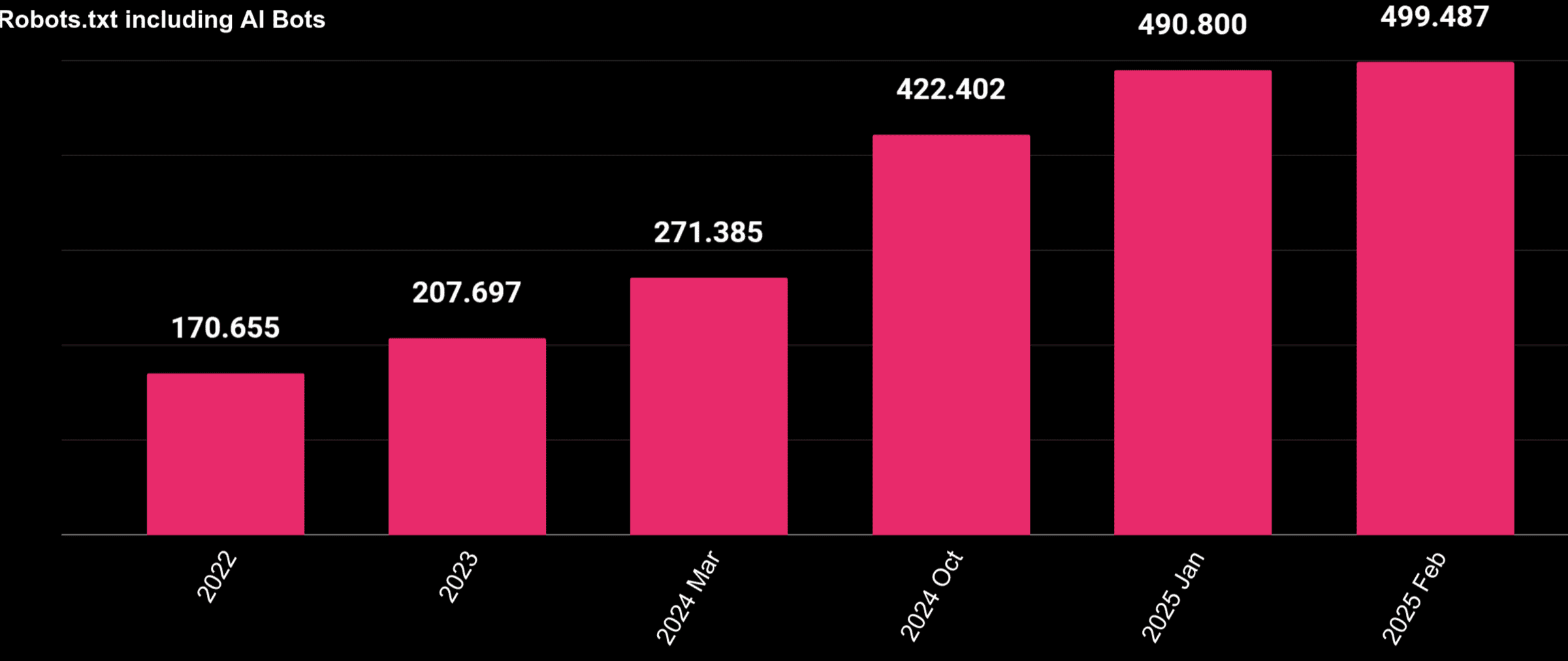
¿Se le está restringiendo el acceso a más webs a los bots de IA?
Esta gráfica muestra cómo ha ido incrementando el número de robots.txt en los que aparecen rastreadores asociados a la Inteligencia Artificial.
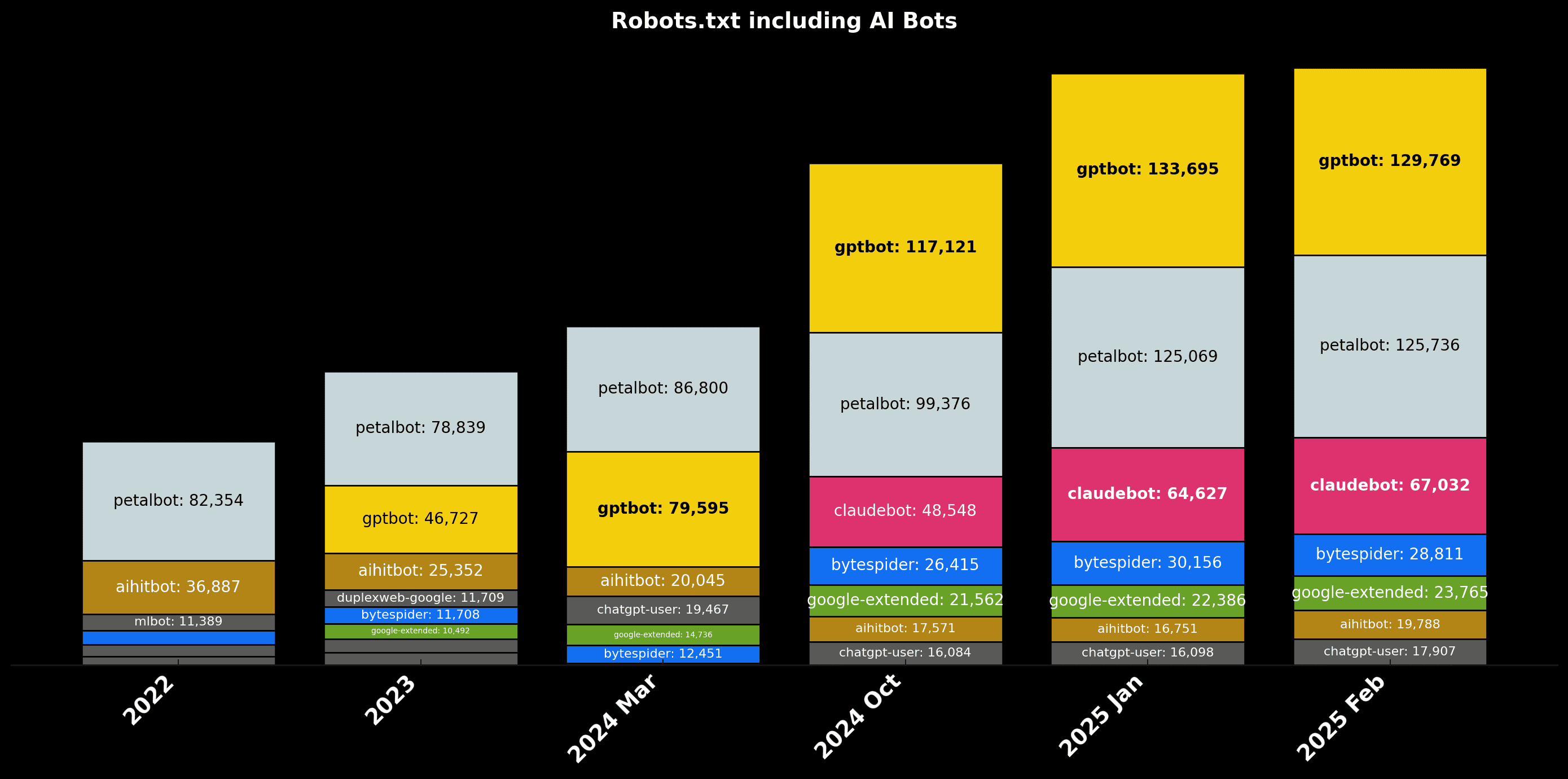
Evolución desglosada de los diferentes rastreadores asociados a la IA
Este es el desglose para ver cuáles crecen más y de qué manera
El bot de chatGPT, gptBot, no aparece hasta 2023, ya que anteriormente apenas nadie había escuchado algo sobre chatGPT, en 2023 irrumpe apareciendo en más de cuarenta y seismil robots.txt, desde entonces el número de sites que le impiden se ha triplicado.
Seguiré publicando datos relacionados con estos rastreos, tanto para monitorizar esta evolución como para otros menesteres :)
