Analizando más de 72 millones de robots.txt
Publicado el 2025-02-12 por Lino Uruñuela
El otro día me dio por descargarme desde CommonCrawl los robots.txt que había procesado el último mes, concretamente este.
Obtener la lista de ficheros Warc
Para obtener todos los robots.txt perimero debes descargar un índice de URLs, en el fichero anterior se listan un total de 90.000 líneas, cada una corresponde a la URL de un fichero Warc.
No penséis que son 90.000 ficheros uno por cada robots.txt, en un fichero Warc están los datos de muchos robots.txt, y la verdad es coñado el procesarlo.
Una vez descargado el fichero podemos visualizar algunas líneas, con el comando zcat
zcat robotstxt.paths.gz| head
crawl-data/CC-MAIN-2025-05/segments/1736703361941.29/robotstxt/CC-MAIN-20250126135402-20250126165402-00000.warc.gz
crawl-data/CC-MAIN-2025-05/segments/1736703361941.29/robotstxt/CC-MAIN-20250126135402-20250126165402-00001.warc.gz
crawl-data/CC-MAIN-2025-05/segments/1736703361941.29/robotstxt/CC-MAIN-20250126135402-20250126165402-00002.warc.gz
crawl-data/CC-MAIN-2025-05/segments/1736703361941.29/robotstxt/CC-MAIN-20250126135402-20250126165402-00003.warc.gz
crawl-data/CC-MAIN-2025-05/segments/1736703361941.29/robotstxt/CC-MAIN-20250126135402-20250126165402-00004.warc.gz
crawl-data/CC-MAIN-2025-05/segments/1736703361941.29/robotstxt/CC-MAIN-20250126135402-20250126165402-00005.warc.gz
crawl-data/CC-MAIN-2025-05/segments/1736703361941.29/robotstxt/CC-MAIN-20250126135402-20250126165402-00006.warc.gz
crawl-data/CC-MAIN-2025-05/segments/1736703361941.29/robotstxt/CC-MAIN-20250126135402-20250126165402-00007.warc.gz
crawl-data/CC-MAIN-2025-05/segments/1736703361941.29/robotstxt/CC-MAIN-20250126135402-20250126165402-00008.warc.gz
crawl-data/CC-MAIN-2025-05/segments/1736703361941.29/robotstxt/CC-MAIN-20250126135402-20250126165402-00009.warc.gz
Ahora vamos adescargar cada uno del los fichros, (aquí el enlace a uno de estos ficheros por si queréis comprobar su contenido) para ello podemos usar un nuevlo cliente que anunció CommonCrawl el otro día, pero en mi caso no me sirvió ya que me limitaba el acceso cada pocas peticiones. Así que fui probando y mejorando lla lista de comandos para optinizar el proceso y al final ejecuto este comando desde el terminal.
export COUNT=0 # Inicia el contador global
zcat robotstxt.paths.gz | while read -r url; do
full_url="https://data.commoncrawl.org/$url"
modified_filename=$(echo "$url" | tr '/' '-')
output_file="./WarcFicheros/$modified_filename"
# Verifica si el archivo ya existe y solo imprime las URLs que deben descargarse
if [ ! -f "$output_file" ]; then
echo "$full_url $output_file"
COUNT=$((COUNT + 1))
if [ $((COUNT % 300)) -eq 0 ]; then
sleep 10
fi
fi
done | xargs -P 3 -n 2 bash -c '
full_url="$0"
output_file="$1"
echo "Descargando: $full_url -> $output_file"
curl -L -o "$output_file" "$full_url"
# Verifica si la descarga fue exitosa
if [ -f "$output_file" ]; then
echo "Descarga completada: $output_file"
else
echo "Error descargando: $full_url"
fi
'
Estse comando descargará la lista de archivos con 3 hilos en paralelo, de ahí que lo haya montado de esta forma, para poder cambiar el número de hilos modificando el valor del parámetro 'P' de xargs, concretamente
xargs -P 3 -n 2 bash -c
Si listamos los ficheros en el directorio veremos:
crawl-data/CC-MAIN-2025-05/segments/1736703361941.29/robotstxt/CC-MAIN-20250126135402-20250126165402-00000.warc.gz
crawl-data/CC-MAIN-2025-05/segments/1736703361941.29/robotstxt/CC-MAIN-20250126135402-20250126165402-00001.warc.gzDeberíamos tener 90.000 ficheros, que en total nos ocuparán 160 GB.
Comprobamos el contenido de alguno de ellos con zcat
zcat ./crawl-data-CC-MAIN-2023-40-segments-1695233505362.29-robotstxt-CC-MAIN-20230921073711-20230921103711-00035.warc.gz
WARC/1.0
WARC-Type: response
WARC-Date: 2023-09-21T07:41:39Z
WARC-Record-ID: <urn:uuid:40fc911d-d257-4a7e-b340-f0b2f97b6912>
Content-Length: 382
Content-Type: application/http; msgtype=response
WARC-Warcinfo-ID: <urn:uuid:8c1a0a1d-1821-4aa4-a3d1-d42414e744bb>
WARC-Concurrent-To: <urn:uuid:3d5c3aba-8b52-41d8-8a87-37fb783b10ac>
WARC-IP-Address: 208.90.215.75
WARC-Target-URI: https://www.prisonradio.org/robots.txt
WARC-Payload-Digest: sha1:WOHI3K4IRHGKRFLRUZOLFYFOJYAJQWPY
WARC-Block-Digest: sha1:O4W7AWS6O6PQ2F73SMD4IUDPHSQJZVD4
WARC-Identified-Payload-Type: text/x-robots
HTTP/1.1 200 OK
Server: nginx/1.24.0
Date: Thu, 21 Sep 2023 07:41:39 GMT
Content-Type: text/plain; charset=utf-8
Content-Length: 120
Connection: keep-alive
X-Powered-By: PHP/8.1.20
Link: <https://www.prisonradio.org/wp-json/>; rel="https://api.w.org/"
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
Sitemap: https://www.prisonradio.org/wp-sitemap.xml
WARC/1.0
WARC-Type: request
WARC-Date: 2023-09-21T07:47:01Z
WARC-Record-ID: <urn:uuid:015dc577-fb14-4ccf-bfa4-9ae3cb695d50>
Content-Length: 267
Content-Type: application/http; msgtype=request
WARC-Warcinfo-ID: <urn:uuid:8c1a0a1d-1821-4aa4-a3d1-d42414e744bb>
WARC-IP-Address: 34.69.219.172
WARC-Target-URI: https://www.protectcuster.com/robots.txt
GET /robots.txt HTTP/1.1
User-Agent: CCBot/2.0 (https://commoncrawl.org/faq/)
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: en-US,en;q=0.5
Accept-Encoding: br,gzip
Extraer el contenido de cada robots.txt
Extraer el contenido de cada robots.txt es lo más complicado ya que quién diseño este tipo de ficheros Warc... algo había fumado :D.
El "problema" es que en los datos de un fichero Warc no hay el código fuente de una URL en concreto sino que contiene el HTML de muchas URLs, por si fuera poco el contenido de cada URL crawleada consta de tres partes:
- Datos de la petición que realizó el crawler de CommonCrawl... (CREO)
- Cabeceras que respondió el servidor de la URL cuándo fue crawleada, en este caso, el robots.txt
- Contenido del robots.txt, el que venos cuándo accedemos desde el navegador
Así que teniendo claro lo que necesitaba le pedí a Gemini que creara un script que obtenga los campos y valores que necesitaba y los fuese guardando en CSV.
Conncretamente, almaceno estos camps en el CSV:
- Nombre_Archivo Warc de dónde se ha ibtenido
- WARC-Target-URI : que es la URL para la que se obtenido este Warc
- Columna1: las cabeceras de la petición
- Columna2: Cabeceras de respuesta del sservuidr
- Columna3: el contenido del robotos.txt, donde remplacé los saltoso de línea por '@@;@@' para luego poder volver a reconstruirlo
Debido a la cantidad de ficheros a procesar, no me gustaría tener que volver a empezar la extracción de todos los ficheros si el proceso fallase así que le indiqué que fuese haciéndolo por lotes, de esta forma podré continuar desde dónde petó la última vez.
Aquí el código dell script completo.
import re
import csv
import os
import gzip
import hashlib
def procesar_archivo_warc(nombre_archivo):
"""
Procesa un archivo WARC (comprimido o no) para extraer información entre delimitadores 'WARC/1.0'
y la transforma en filas con 5 columnas, nombre del archivo, URI, y las 3 columnas.
Args:
nombre_archivo: La ruta al archivo WARC.
Returns:
Una lista de listas, donde cada lista interior representa una fila con 5 columnas
"""
filas = []
codificaciones = ['utf-8', 'iso-8859-1', 'windows-1252', 'latin1'] # Lista de codificaciones a probar
open_function = open # Por defecto abrir con open
open_mode = 'r'
if nombre_archivo.endswith('.gz'):
try:
with open(nombre_archivo, 'rb') as f:
magic_number = f.read(2)
if magic_number == b'\x1f\x8b': # Comprobar si es un archivo gzip válido
open_function = gzip.open
open_mode = 'rt' # Para leer ficheros en texto
except Exception as e:
print(f"Error verificando gzip en {nombre_archivo}: {e}, abriendo como texto")
open_function = open # Si hay error, volver a abrir como texto.
open_mode = 'r'
for codificacion in codificaciones:
try:
with open_function(nombre_archivo, open_mode, encoding=codificacion) as f:
try: # Add try-except block here
contenido = f.read()
except EOFError as e:
print(f"Warning: Gzip file {nombre_archivo} seems to be corrupted or truncated. Skipping. Error: {e}")
return [] # Return empty list to indicate no rows processed from this file
bloques = re.split(r'(?=WARC/1\.0)', contenido)[1:] # Separar por WARC/1.0, ignorando el primer split si no existe.
for bloque in bloques:
bloque = bloque.strip()
# Busca WARC-Target-URI
uri_match = re.search(r'WARC-Target-URI:\s*(.*)', bloque)
uri = uri_match.group(1).strip() if uri_match else "-"
partes = re.split(r'\n\s*\n', bloque) # Separar por saltos de línea vacíos
# Remplazamos todos los saltos de línea por @@;@@
columnas = []
for parte in partes:
parte = parte.replace('\n', '@@;@@').strip()
columnas.append(parte)
# Ajustamos el número de columnas si es necesario
while len(columnas) < 3:
columnas.append("-")
filas.append([os.path.basename(nombre_archivo), uri] + columnas[:3]) # Asegurar que solo hay 5 columnas por fila.
return filas # Si decodifica bien, retorna directamente
except UnicodeDecodeError:
continue # Si hay un error, prueba la siguiente codificación
print(f"No se pudo decodificar el archivo: {nombre_archivo} con las codificaciones: {codificaciones}")
return [] # Si ninguna codificación funciona, retorna una lista vacía.
def procesar_directorio_warc(directorio_warc, directorio_salida, archivos_por_salida=100, fichero_procesados='ficherosProcesados.txt', inicio_contador=84000):
"""
Procesa todos los archivos .warc o .warc.gz de un directorio y guarda los resultados en archivos CSV comprimidos
separados. Genera un archivo de salida por cada N archivos de entrada.
Args:
directorio_warc: La ruta al directorio con los archivos WARC.
directorio_salida: La ruta al directorio donde se guardarán los CSV.
archivos_por_salida: Número de archivos WARC de entrada por archivo CSV de salida.
fichero_procesados: La ruta al fichero de texto con la lista de ficheros ya procesados
inicio_contador: El contador por el que se debe empezar.
"""
global contador_ficheros
contador_ficheros = inicio_contador//archivos_por_salida + 1
archivos_procesados = 0
if not os.path.exists(directorio_salida):
os.makedirs(directorio_salida)
filas_buffer = [] # Almacenar filas en memoria antes de escribir al archivo
# Lee los ficheros procesados desde el fichero
processed_files = set()
try:
with open(fichero_procesados, 'r', encoding='utf-8') as f:
for line in f:
processed_files.add(line.strip())
except FileNotFoundError:
print(f"El archivo {fichero_procesados} no se encontró. Se comenzará desde el principio.")
for filename in os.listdir(directorio_warc):
if filename.endswith((".warc", ".warc.gz")):
filepath = os.path.join(directorio_warc, filename)
if filename not in processed_files:
filas_archivo = procesar_archivo_warc(filepath)
if filas_archivo:
filas_buffer.extend(filas_archivo)
archivos_procesados += 1
else:
print(f"No se encontraron filas para procesar en {filename}")
# Check if it's time to write to an output file
if archivos_procesados == archivos_por_salida:
# Crear el nombre del archivo de salida
output_filename = os.path.join(directorio_salida, f"warc_batch-{contador_ficheros * archivos_por_salida}.csv.gz")
# Escribir y comprimir el buffer a un fichero
with gzip.open(output_filename, 'wt', encoding='utf-8', newline='') as gzfile:
writer = csv.writer(gzfile, quoting=csv.QUOTE_ALL)
writer.writerow(['Nombre_Archivo', 'WARC-Target-URI', 'Columna1', 'Columna2', 'Columna3']) # Escribe la cabecera
writer.writerows(filas_buffer)
print(f"Fichero generado: {output_filename}")
# Resetear contadores y limpiar buffer
filas_buffer = []
archivos_procesados = 0
contador_ficheros += 1
# Añadir los nombres de ficheros al fichero de procesos.
with open(fichero_procesados, "a", encoding="utf-8") as f:
for filename_procesado in os.listdir(directorio_warc): #recorrer todos los fichero y anotar los que ya hemos leido.
if filename_procesado.endswith((".warc", ".warc.gz")):
f.write(f"{filename_procesado}\n") #add filename al archivo, para la siguiente ejecución.
else:
print(f"El archivo {filename} ya ha sido procesado.")
# Procesar cualquier fila restante en el buffer, si hay.
if filas_buffer:
output_filename = os.path.join(directorio_salida, f"warc_batch-{contador_ficheros * archivos_por_salida}.csv.gz")
with gzip.open(output_filename, 'wt', encoding='utf-8', newline='') as gzfile:
writer = csv.writer(gzfile, quoting=csv.QUOTE_ALL)
writer.writerow(['Nombre_Archivo', 'WARC-Target-URI', 'Columna1', 'Columna2', 'Columna3']) # Escribe la cabecera
writer.writerows(filas_buffer)
print(f"Fichero generado: {output_filename}")
contador_ficheros += 1
# Añadir los nombres de ficheros al fichero de procesos.
with open(fichero_procesados, "a", encoding="utf-8") as f:
for filename_procesado in os.listdir(directorio_warc): #recorrer todos los fichero y anotar los que ya hemos leido.
if filename_procesado.endswith((".warc", ".warc.gz")):
f.write(f"{filename_procesado}\n") #add filename al archivo, para la siguiente ejecución.
if __name__ == '__main__':
directorio_warc = './WarcFicheros' # Reemplaza con la ruta a tu directorio de archivos WARC
directorio_salida = './WarcCSV' # Reemplaza con la ruta a tu directorio de salida para el CSV
archivos_por_salida = 100 # Número de archivos WARC de entrada por archivo CSV de salida
fichero_procesados = './listaFicherosProcesados.txt'
inicio_contador = 84300
procesar_directorio_warc(directorio_warc, directorio_salida, archivos_por_salida, fichero_procesados,inicio_contador)
print(f"Procesamiento completado, resultados guardados en {directorio_salida}")
Cuando lo ejecutamos, se procesara cada fichero Warc, extrallendo los campos y valores que yo quería analizar. Cada 100 ficheros Warc procesados, el script volcará los datos a un CSV.
Cuando termine de procesar toda la carpeta habrá 900 ficheros CSV con los datos extraídos. Por ejemplo, así se ven las tres primeras líneas de uno de estos CSV
"Nombre_Archivo","WARC-Target-URI","Columna1","Columna2","Columna3"
"crawl-data-CC-MAIN-2023-40-segments-1695233506420"."84-robotstxt-CC-MAIN-20230922134342-20230922164342-00812.warc.gz","-","WARC/1.0@@;@@WARC-Type: warcinfo@@;@@WARC-Date: 2023-09-22T13:43:42Z@@;@@WARC-Record-ID: <urn:uuid:4a933997-e117-4611-8888-7503d6004462>@@;@@Content-Length: 500@@;@@Content-Type: application/warc-fields@@;@@WARC-Filename: CC-MAIN-20230922134342-20230922164342-00812.warc.gz","isPartOf: CC-MAIN-2023-40@@;@@publisher: Common Crawl@@;@@description: Wide crawl of the web for September/October 2023@@;@@operator: Common Crawl Admin (info@commoncrawl.org)@@;@@hostname: ip-10-67-67-129@@;@@software: Apache Nutch 1.19 (modified, https://github.com/commoncrawl/nutch/)@@;@@robots: checked via crawler-commons 1.5-SNAPSHOT (https://github.com/crawler-commons/crawler-commons)@@;@@format: WARC File Format 1.1@@;@@conformsTo: https://iipc.github.io/warc-specifications/specifications/warc-format/warc-1.1/","-"
"crawl-data-CC-MAIN-2023-40-segments-1695233506420"."84-robotstxt-CC-MAIN-20230922134342-20230922164342-00812.warc.gz","http://180.180.244.229/robots.txt","WARC/1.0@@;@@WARC-Type: request@@;@@WARC-Date: 2023-09-22T13:52:08Z@@;@@WARC-Record-ID: <urn:uuid:5b68084b-9860-4109-807e-b2d0630c380a>@@;@@Content-Length: 261@@;@@Content-Type: application/http; msgtype=request@@;@@WARC-Warcinfo-ID: <urn:uuid:4a933997-e117-4611-8888-7503d6004462>@@;@@WARC-IP-Address: 180.180.244.229@@;@@WARC-Target-URI: http://180.180.244.229/robots.txt","GET /robots.txt HTTP/1.1@@;@@User-Agent: CCBot/2.0 (https://commoncrawl.org/faq/)@@;@@Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8@@;@@Accept-Language: en-US,en;q=0.5@@;@@Accept-Encoding: br,gzip@@;@@Host: 180.180.244.229@@;@@Connection: Keep-Alive","-"
Consultando datos de robots.txt usando SQL
Ahora que tengo los 900 ficheros csv con los datos de los robots.txt puedo ejecutar consultas SQL sobre ellos. En este ejemplo vamos a contar cuántoas URLs de robots.txt hay en total, el cuántos hostnames y dominios en distribuyen.
SELECT
uniqExact(`WARC-Target-URI`) as robotstxt,
countDistinct(cutToFirstSignificantSubdomain(`WARC-Target-URI`)) as Dominios,
count() AS totales,
countDistinct(domain(`WARC-Target-URI`)) AS hostnames
FROM file('2025-enero-robots/*.csv.gz', 'CSVWithNames')
Ejemplo del resultado de esta consulta SQL sobre todos los ficheros :
Row 1:
----------
robotstxt: 72162483 -- 72.16 million
Dominios: 46682993 -- 46.68 million
totales: 190017148 -- 190.02 million
hostnames: 62785043 -- 62.79 million
En total hay mas de 200 millones de rastreos a robots.txt, a un total de más de 72millones de URLs únicas de robots.txt, que existen en un total de más de 46 millones de dominios.. casi nada!
SQL - Filtrando datos
Comencemos por una sencilla SQL, obtendremos el contenido de cada robots.txt y extraemos los diferentes User Agent para cada uno.
Obtener para cada hostname (subdominio + dominio) los diferentes User-Agent definidos en su robots.txt
SELECT
cutToFirstSignificantSubdomain(`WARC-Target-URI`) as dominio,
domain(`WARC-Target-URI`) as hostName,
`WARC-Target-URI` as robotsURL,
arrayFlatten(groupUniqArray(extractAll(assumeNotNull(Columna3), '(?i)User-agent[\\s]?:[\\s]?(.*?)(?:@@;@@|$)'))) AS Bots,
length(Bots) as numUserAgents,
groupArray(Columna3) as contenidoRobots
FROM file('2025-enero-robots/*.csv.gz', 'CSVWithNames') where Columna3 not like '%<html>%' and Columna3 not like '%<head>%' group by robotsURL limit 20
FORMAT Vertical
Con esta SQL para cada URL de robots.txt obtenemos los diferentes User Agents que tiene definido en su contenido.
Row 1:
---------------
dominio: vinewire.biz
hostName: vinewire.biz
robotsURL: http://vinewire.biz/robots.txt
Bots: ['*']
numUserAgents: 1
contenidoRobots: ['-','User-agent: *@@;@@Disallow: /wp-admin/@@;@@Allow: /wp-admin/admin-ajax.php']
Row 2:
---------------
dominio: desa-trade.com
hostName: www.desa-trade.com
robotsURL: https://www.desa-trade.com/robots.txt
Bots: ['Googlebot','googlebot-image','googlebot-mobile','MSNBot','Slurp','Teoma','Gigabot','Robozilla','Nutch','ia_archiver','baiduspider','naverbot','yeti','yahoo-mmcrawler','psbot','yahoo-blogs/v3.9','*']
numUserAgents: 17
contenidoRobots: ['-','# robots.txt dosyası https://www.ihs.com.tr/seo/robots-txt-olusturucu aracı kullanılarak oluÅturulmuÅtur.@@;@@User-agent: Googlebot@@;@@Disallow: @@;@@User-agent: googlebot-image@@;@@Disallow: @@;@@User-agent: googlebot-mobile@@;@@Disallow: @@;@@User-agent: MSNBot@@;@@Disallow: @@;@@User-agent: Slurp@@;@@Disallow: @@;@@User-agent: Teoma@@;@@Disallow: @@;@@User-agent: Gigabot@@;@@Disallow: @@;@@User-agent: Robozilla@@;@@Disallow: @@;@@User-agent: Nutch@@;@@Disallow: @@;@@User-agent: ia_archiver@@;@@Disallow: @@;@@User-agent: baiduspider@@;@@Disallow: @@;@@User-agent: naverbot@@;@@Disallow: @@;@@User-agent: yeti@@;@@Disallow: @@;@@User-agent: yahoo-mmcrawler@@;@@Disallow: @@;@@User-agent: psbot@@;@@Disallow: @@;@@User-agent: yahoo-blogs/v3.9@@;@@Disallow: @@;@@User-agent: *@@;@@Disallow: @@;@@Disallow: /cgi-bin/@@;@@Sitemap: http://www.desa-trade.com/sitemap.xml']
Si os fijáis en el contenido de los robots.txt en vez de saltos de línea hay '@@;@@', es la primera idea que se me ocurrió, y es útil, puedo volver a tranformar el robots.txt remplazandolos de nuevo por saltos de línea
SELECT
cutToFirstSignificantSubdomain(`WARC-Target-URI`) as dominio,
domain(`WARC-Target-URI`) as hostName,
`WARC-Target-URI` as robotsURL,
arrayFlatten(groupUniqArray(extractAll(assumeNotNull(Columna3), '(?i)User-agent[\\s]?:[\\s]?(.*?)(?:@@;@@|$)'))) AS Bots,
length(Bots) as numUserAgents,
groupArray(Columna3) as contenidoRobots ,
groupArray(replaceRegexpAll(Columna3,'@@;@@','\\n')) as contenidoRobotsFormateado
FROM file('2025-enero-robots/*.csv.gz', 'CSVWithNames') where Columna3 not like '%<html>%' and Columna3 not like '%<head>%' group by robotsURL limit 20
FORMAT Vertical
Con un pequeño remplazo de caracteres podemos volver a mostrar los saltos de línea.
Row 2:
---------------
dominio: desa-trade.com
hostName: www.desa-trade.com
robotsURL: https://www.desa-trade.com/robots.txt
Bots: ['Googlebot','googlebot-image','googlebot-mobile','MSNBot','Slurp','Teoma','Gigabot','Robozilla','Nutch','ia_archiver','baiduspider','naverbot','yeti','yahoo-mmcrawler','psbot','yahoo-blogs/v3.9','*']
numUserAgents: 17
contenidoRobots: ['-','# robots.txt dosyası https://www.ihs.com.tr/seo/robots-txt-olusturucu aracı kullanılarak oluÅturulmuÅtur.@@;@@User-agent: Googlebot@@;@@Disallow: @@;@@User-agent: googlebot-image@@;@@Disallow: @@;@@User-agent: googlebot-mobile@@;@@Disallow: @@;@@User-agent: MSNBot@@;@@Disallow: @@;@@User-agent: Slurp@@;@@Disallow: @@;@@User-agent: Teoma@@;@@Disallow: @@;@@User-agent: Gigabot@@;@@Disallow: @@;@@User-agent: Robozilla@@;@@Disallow: @@;@@User-agent: Nutch@@;@@Disallow: @@;@@User-agent: ia_archiver@@;@@Disallow: @@;@@User-agent: baiduspider@@;@@Disallow: @@;@@User-agent: naverbot@@;@@Disallow: @@;@@User-agent: yeti@@;@@Disallow: @@;@@User-agent: yahoo-mmcrawler@@;@@Disallow: @@;@@User-agent: psbot@@;@@Disallow: @@;@@User-agent: yahoo-blogs/v3.9@@;@@Disallow: @@;@@User-agent: *@@;@@Disallow: @@;@@Disallow: /cgi-bin/@@;@@Sitemap: http://www.desa-trade.com/sitemap.xml']
"contenidoRobotsFormateado: ['-',
'# robots.txt dosyası https://www.ihs.com.tr/seo/robots-txt-olusturucu aracı kullanılarak oluÅturulmuÅtur.
User-agent: Googlebot
Disallow:
User-agent: googlebot-image
Disallow:
User-agent: googlebot-mobile
Disallow:
User-agent: MSNBot
Disallow:
User-agent: Slurp
Disallow:
User-agent: Teoma
Disallow:
User-agent: Gigabot
Disallow:
User-agent: Robozilla
Disallow:
User-agent: Nutch
Disallow:
User-agent: ia_archiver
Disallow:
User-agent: baiduspider
Disallow:
User-agent: naverbot
Disallow:
User-agent: yeti
Disallow:
User-agent: yahoo-mmcrawler
Disallow:
User-agent: psbot
Disallow:
User-agent: yahoo-blogs/v3.9
Disallow:
User-agent: *
Disallow:
Disallow: /cgi-bin/
Sitemap: http://www.desa-trade.com/sitemap.xml']"
¿Cuál será el robots.txt con más User Agents diferentes?
Hay algunos dominios que tienen una gran cantidad de User Agents especificados en su robots.txt, no sé ni de dónde los habrán sacado!, aquí algunos ejemplos de robots.txt con más de 1.600 User-Agent diferentes!
SELECT numUserAgents,dominio,robotsURL FROM (
SELECT
cutToFirstSignificantSubdomain(`WARC-Target-URI`) AS dominio,
domain(`WARC-Target-URI`) AS hostName,
`WARC-Target-URI` AS robotsURL,
arrayDistinct(arrayFlatten(groupUniqArray(extractAll(assumeNotNull(Columna3), '(?i)User-agent[\\s]?:[\\s]?(.*?)(?:@@;@@|$)')))) AS Bots,
length(Bots) AS numUserAgents
FROM file('2025-enero-robots/*.csv.gz', 'CSVWithNames')
WHERE (Columna3 NOT LIKE '%<html>%') AND (Columna3 NOT LIKE '%<head>%')
GROUP BY robotsURL
)
order by numUserAgents desc limit 10
numUser
Agents dominio URL
--- --------------- ------------------------------------
1854 diananoclegi.pl https://diananoclegi.pl/robots.txt
1829 dotcom.co.il https://themes.dotcom.co.il/robots.txt
1829 adapelleg.com https://www.adapelleg.com/robots.txt
1829 merontal.co.il https://www.merontal.co.il/robots.txt
1829 adapelleg.com http://www.adapelleg.com/robots.txt
1829 rahan.co.il http://www.rahan.co.il/robots.txt
1829 dotcom.co.il https://site.dotcom.co.il/robots.txt
1829 galileemusic.org.il https://www.galileemusic.org.il/robots.txt
1829 galileemusic.org.il http://www.galileemusic.org.il/robots.txt
1829 tamargerchuk.co.il https://www.tamargerchuk.co.il/robots.txt
Podemos accedr al contenido del robots.txt que más User Agents tiene definido en su robots para comprobarlo
¿Cuántos dominios bloquean a los crawlers para IA?
Vamos a contabilizar cuántos dominios, subdominios y robots.txt hay que estén bloqueando a los crawlers de Inteligencia Artificial y cuántos no lo hacen, por supuesto, esta monitorización será útil cuándo compare con otro rastreo anterior o posterior, para ver la evolución y poder ver cómo "reaccionamos" ante la IA.
Cada vez hay más empresas que rastrean internet para obtener la fuente del conocimeinto de sus futuros modelos de lenguaje, de momento solo he comprobado estos Bots, 'OAI', 'ChatGPT', 'GPTBot', 'PerplexityBot', 'Claude', 'Google-Extended', en posteriores artículos veremos si termino de definir una lista completa.
SELECT
uniqExactIf(cutToFirstSignificantSubdomain(`WARC-Target-URI`),multiSearchAnyCaseInsensitive(Columna3, ['OAI', 'ChatGPT', 'GPTBot', 'PerplexityBot', 'Claude', 'Google-Extended']) != 0) AS "Dominios que bloquean IA",
uniqExactIf(cutToFirstSignificantSubdomain(`WARC-Target-URI`),multiSearchAnyCaseInsensitive(Columna3, ['OAI', 'ChatGPT', 'GPTBot', 'PerplexityBot', 'Claude', 'Google-Extended']) = 0) AS "Dominios que NO bloquaen IA",
uniqExactIf(domain(`WARC-Target-URI`),multiSearchAnyCaseInsensitive(Columna3, ['OAI', 'ChatGPT', 'GPTBot', 'PerplexityBot', 'Claude', 'Google-Extended']) != 0) AS "Hostnames que bloquean IA",
uniqExactIf(domain(`WARC-Target-URI`),multiSearchAnyCaseInsensitive(Columna3, ['OAI', 'ChatGPT', 'GPTBot', 'PerplexityBot', 'Claude', 'Google-Extended']) = 0) AS "Hostnames que NO bloquean IA",
uniqExactIf(`WARC-Target-URI`,multiSearchAnyCaseInsensitive(Columna3, ['OAI', 'ChatGPT', 'GPTBot', 'PerplexityBot', 'Claude', 'Google-Extended']) != 0) AS "URLs de robots.txt qie bloquean UA",
uniqExactIf(`WARC-Target-URI`,multiSearchAnyCaseInsensitive(Columna3, ['OAI', 'ChatGPT', 'GPTBot', 'PerplexityBot', 'Claude', 'Google-Extended']) = 0) AS "URLs de robots.txt qie NO bloquean UA"
FROM file('2025-enero-robots/*.csv.gz', 'CSVWithNames')
FORMAT VerticalRow 1:
Dominios que bloquean IA: 152859
Dominios que NO bloquean IA: 46682993
Hostnames que bloquean IA: 251277
Hostnames que NO bloquean IA: 62785043
URLs de robots.txt qie bloquean UA: 263844
URLs de robots.txt qie NO bloquean UA: 72162483
¿En cuántos robots.txt aparece cada User Agent?
A continuación muestro una tabla con los Users Agents que en más robots.txt aparecen.
VAmos a contar en cuántos robts.txt diferentes aparece cada uno de los Usaer-Agents
SELECT
trimBoth(arrayJoin(bots)) AS BOTS,sum(1) as contador
FROM (
SELECT
`WARC-Target-URI`,
arrayDistinct(arrayFlatten(arrayConcat(groupArray(extractAll(lower(assumeNotNull(Columna3)),
'(?i)User-agent[\\s]?:[\\s]?(.*?)(?:@@;@@|\$)'))))) AS bots
FROM
Robots2
GROUP BY `WARC-Target-URI`
)
GROUP BY BOTS
ORDER BY contador desc
Además vamos a realizar la misma consulta, pero solamente para los UsearAgent que hemos identificaddo como crawlers de IAm aquí amos resultados.
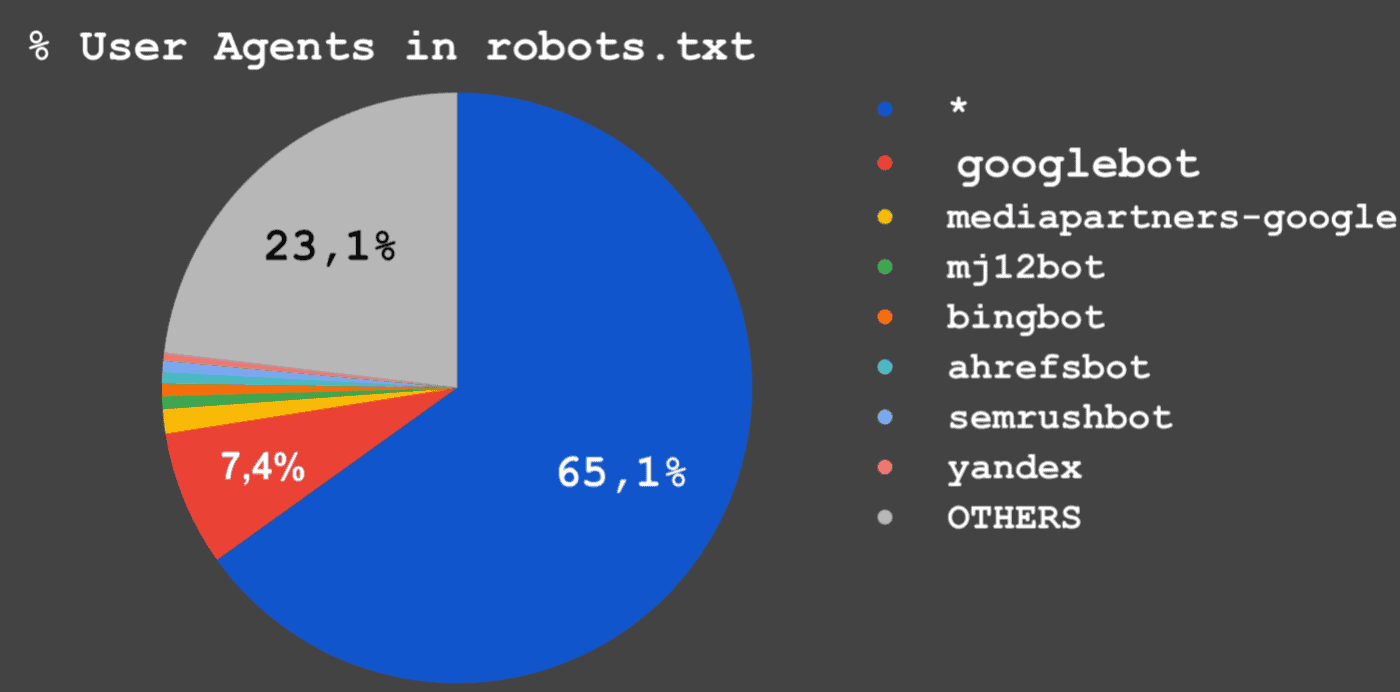
User Agent robots.txt
----------------------------------
* 34.752.197
googlebot 3.957.246
mediapartners-google 714.718
mj12bot 369.283
bingbot 363.756
ahrefsbot 331.413
semrushbot 329.690
yandex 218.709
OTHERS 12.343.460
IA Bot robots.txt
-----------------------------
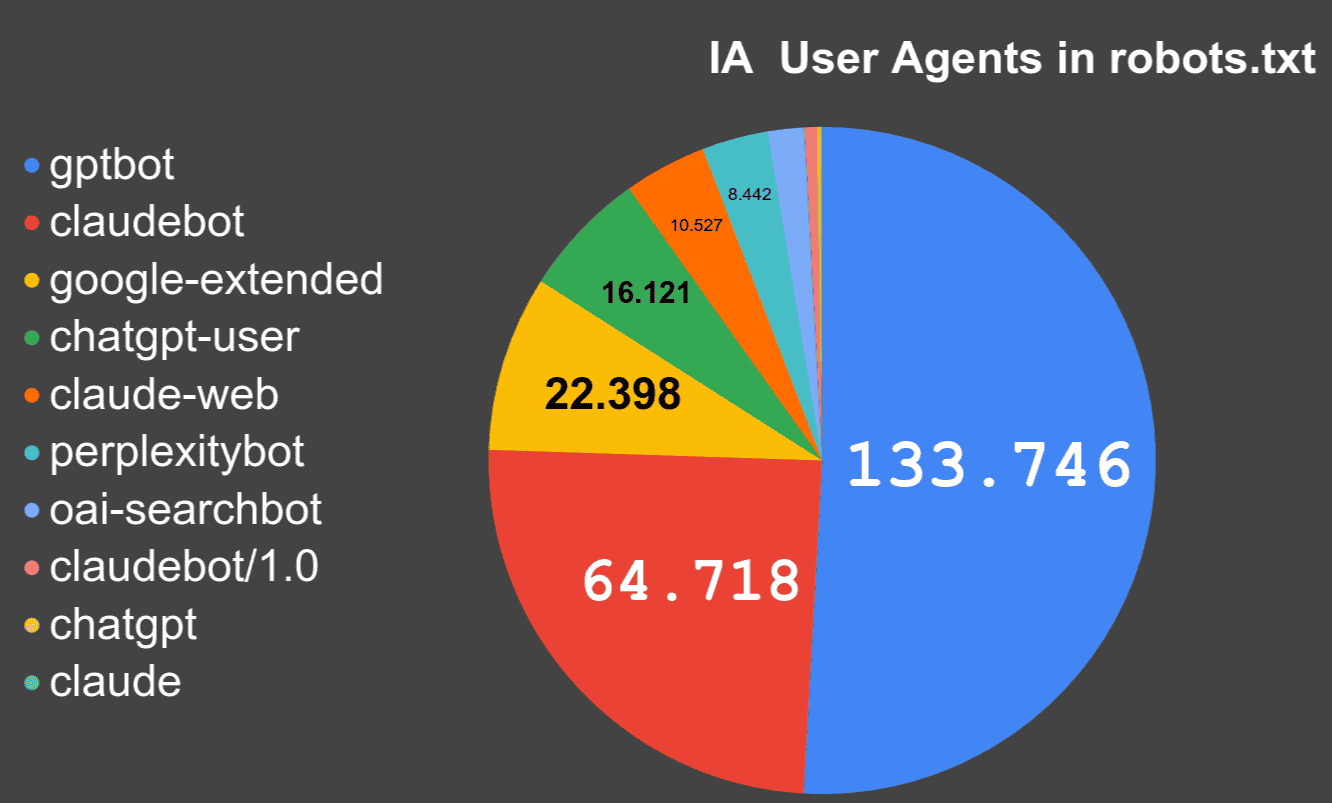
gptbot 133.746
claudebot 64.718
google-extended 22.398
chatgpt-user 16.121
claude-web 10.527
perplexitybot 8.442
oai-searchbot 4.624
claudebot/1.0 1.578
chatgpt 451
Gráfica que muestra en cuántos robots.txt aprece cada User Agent
User Agents in robots.txt
IA User Agents in robots.txt
¿Cuántos robots.txt añaden Sitemaps?
SELECT
uniqExactIf(`WARC-Target-URI`,match(lower(Columna3),'sitemap*:')) as `Robots.txt que contienen Sitemaps:`
FROM file('2025-enero-robots/*.csv.gz', 'CSVWithNames')Robots.txt que contienen Sitemaps: 6158128

Cantidad de Disallow vs Cantidad de Allow
Esta es una de las ideas que MJ Cachón me dio cuando la dije qué estaba haciendo, ¿podemos saber el número de 'Allows' y cuántas 'Disallows', eso es fácil :)
SELECT
sumIf(countSubstringsCaseInsensitive(lower(Columna3),'allow'),match(lower(Columna3),'allow')) as numAllows,
sumIf(countSubstringsCaseInsensitive(lower(Columna3),'disallow'),match(lower(Columna3),'disallow')) as numDisallows
FROM file('2025-enero-robots/*.csv.gz', 'CSVWithNames')Row 1:
--------
numAllows: 388799659 -- 388.80 million
numDisallows: 334261065 -- 334.26 million
Hasta aquí hemos llegado hoy con el análisis de robots.txt, seguiré actualizando y conpartiendo más cosas según vaya realizando los retos que MJ me planteó.
