Notas semanales - Semana 6 - (SEO & IA)
Publicado el 2025-02-09 por Lino Uuñuela
Un repaso a los principales buscadores: ¿Google está perdiendo posiciones?
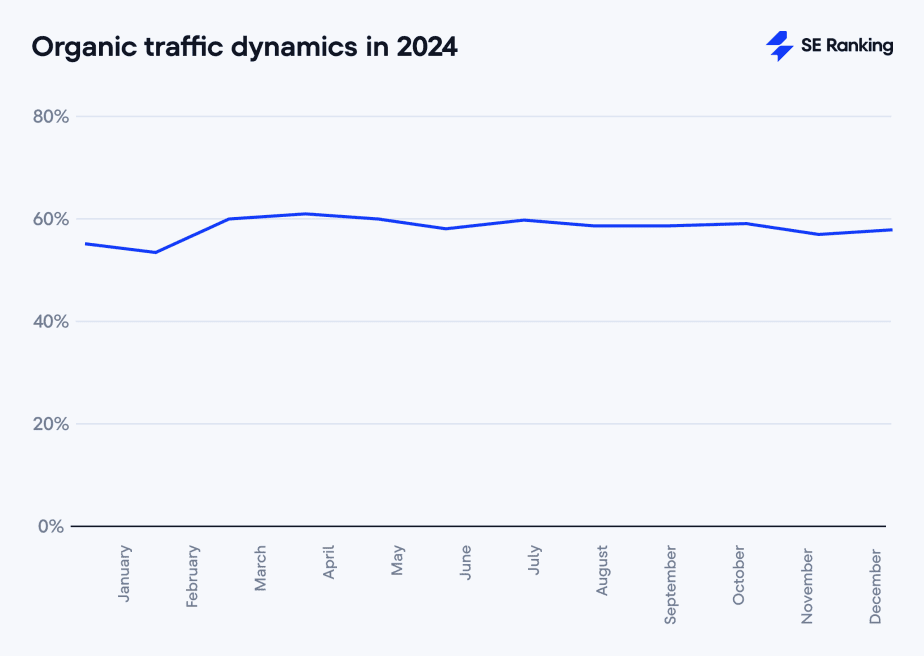
- El tráfico orgánico en general aumento del 2,39 % de enero a diciembre.
Ver fuente original
- El tráfico orgánico en EE. UU. disminuyó un 15,53 %.
- En el Reino Unido se observó una disminución del 4,97 % en el tráfico orgánico.
- En España (57,42 %) se mantiene la cuota de tráfico orgánico.
Hay muchas dudas, opiniones y "estudios" sobre cómo la llegada de la IA afecta a las fuentes de tráfico de las páginas web, no solo las fuentes de tráfico sino el volumen total que los buscadores envian a los sitios.
Este artículo de SERranking ofrece un completo estudio, del tráfico orgánico y el uso de la IA en diferentes mercados.
[Fuente:Seranking]
Celebrando los 50.000 agentes personalizados creados en you.com | You.com
Menos de un año después, pasamos de ser un motor de búsqueda a un asistente de IA generativo y multiplicamos por diez su uso, lo que refleja el cambio significativo en el comportamiento del consumidor que ya se estaba produciendo
Ver fuente original
Otro indicio de que el comportamiento de los usuarios está cambiando, You.com describe en una frase de este artículo el cambio que ha hecho la empresa en un año, de ser un buscador a ser un asisntente de IA.
A Comprehensive Framework to Operationalize Social Stereotypes for Responsible AI Evaluations
El artículo habla sobre cómo evaluar y manejar los estereotipos sociales en la IA IA.
Añadiendo la implicación en la inferencia del lenguaje natural (NLI)
Paper dónde se explora cómo la IA puede mejorar la comprensión del lenguaje humano, especialmente en el área de inferencia implícita.
Ver fuente original
Cuándo hablamos no siempre expresamos directamente lo que queremos decir, ni falta que hace, porque tienen un significado ímplicito de por sí. Sin embargo, los modelos de lenguaje actuales tienen dificultades en reconocer inferencias implícitas.
La inferencia implícita es el proceso mediante el cual se extrae información o significado de un texto sin que esté expresado de manera explícita. Es decir, se trata de deducir algo que no se dice directamente, pero que se puede inferir a partir del contexto, el conocimiento del mundo o las reglas del lenguaje.
Ejemplo:
"Alex caminó hacia la caja en el supermercado. El cajero le preguntó si había traído una bolsa para sus compras. Con un gruñido molesto, Alex se maldijo por haber olvidado y le dijo al cajero que tenía que comprar una bolsa esa noche."
Inferencias Explícitas:
- Alex fue a la caja en el supermercado.
- El cajero preguntó si tenía una bolsa.
- Alex olvidó llevar una bolsa y decidió comprar una.
Inferencias Implícitas:
- Alex está molesto porque olvidó traer su bolsa.
- El supermercado no proporciona bolsas gratuitas.
- Alex probablemente es alguien que suele llevar su propia bolsa (de lo contrario, no estaría tan molesto).
Comprensión de las consultas de búsqueda de usuarios usando LLM
Por eso, agregamos una metaetiqueta para marcar las secciones con corrección ortográfica y decidimos combinar estas dos tareas en una sola solicitud.
En el lado de RAG,ampliamos el texto de consulta de entrada con los nombres de las empresas que se han visto para esa consulta. Esto ayuda el modelo a aprender y distinguir las diversas facetas de los nombres de empresa de temas, ubicaciones y errores ortográficos comunes.
Ver fuente original
¿Cómo llevó Yelp.com el uso de LLMs a millones de búsquedas diarias?
Yelp, la gran plataforma de reseñas, también comparte cómo hace las cosas internamente, en este artículo muestran como segmentan y clasifican las búsquedas de los usuario y cómo usan los errores ortográficos para "vitaminar" la query.
En su proceso, realizaba dos tareas diferentes:
- Segmentación de consultas : dada una consulta, quieren segmentar y etiquetar las partes semánticas las consultas. Por ejemplo, “restaurantes que aceptan mascotas en sf abiertos ahora” podría tener la siguiente segmentación: {tema} restaurantes que aceptan mascotas {ubicación} sf {tema} {hora} abiertos ahora. Esto les vale por ejemplo para añadir a la frase de búsqueda del usuario el el nombre de la localización si procede y así que coincida mejor con la intención del usuario.
- Frases y fragmentos destacados de reseñas : mostrar en cada resultado de una búsqueda el fragmenteo de texto a destacar que muestre la información más útil para que el usuario tome la decisión correcta de si le interesa o no acceder es un arte. Los SEOs llevamos viéndolos en las Serps muchos años... Pues eso es lo que explican, por ejemplo, si un usuario busca "cena antes de un espectáculo de Broadway", ponen en negrita la frase "cena previa al espectáculo" como fragmento de reseña es estp una información muy útil para el usuario.
Añadieron una metaetiqueta para marcar las secciones que habían sido corregidas ortográficamente y añadieron al texto de consulta de entrada los nombres de las empresas que ya se han visto para esa consulta. Según dicen "esto ayuda al modelo a aprender y distinguir las muchas facetas de los nombres de las empresas de los temas, ubicaciones y errores ortográficos comunes. Esto es muy útil tanto para la segmentación como para la corrección ortográfica (por lo que fue otra razón para combinar las dos tareas)"
Me encantan este tipo de artículos, que no son simplemente teoría sino implementaciones en el mundo real.
Confesiones de Jared Palmer (VP de Vercel.com)
Hemos estado ocultando partes de las respuestas de v0 a los usuarios desde septiembre. Desde el lanzamiento de la experiencia web de DeepSeek y su recepción positiva, nos damos cuenta de que fue un error. A partir de ahora, también mostramos el resultado completo de v0 en cada respuesta. Esta es una experiencia de usuario mucho mejor porque parece más rápida y enseña a los usuarios finales cómo dar indicaciones de manera más efectiva.
Ver fuente original
Jared Palmer (vicepresindente de Vercel) confiesa que han estado ocultando partes de las respuestas de la versión v0 a los usuarios desde septiembre. Tras el lanzamiento de la experiencia web de DeepSeek y su positiva recepción, se dan cuenta de que fue un error.
A partir de ahora, mostrarán la salida completa de v0 en cada respuesta para mejorar la experiencia del usuario (UX), haciéndola sentir más rápida y enseñando a los usuarios finales cómo realizar indicaciones (prompts) de manera más efectiva.
A Scalable Crawling Algorithm Utilizing Noisy Change-Indicating Signals
Se ha estimado que hasta el 53% de los rastreos de los principales motores de búsqueda es redundante (Cloudfare, 2021), en el sentido de que el rastreador visita una versión inalterada de una página web.
Existe una creciente conciencia del costo ambiental y monetario de esta redundancia, lo que motivó iniciativas para proporcionar señales adicionales a los rastreadores, lo que les permitiría, en teoría, mejorar sus políticas de rastreo.
Ver fuente original
Para más explicaciones en mi artículo ¿Cómo decide Google que URL debe rastrear? hablo sobre este paper.
Sistema usado por Pinterest para su buscador
En la industria se ha adoptado ampliamente un enfoque basado en dos torres [6], donde una torre aprende la incrustación de consultas y la otra aprende la incrustación de elementos.
Ver fuente original
Los sistemas de recomendación modernos a gran escala, como el de Pinterest, suelen tener múltiples etapas. La recuperación (retrieval) selecciona candidatos de miles de millones de usuarios que tiene la plataforma, y el ranking predice con qué pins interactuará un usuario. Anteriormente, Pinterest usaba métodos heurísticos (reglas predefinidas), como gráficos de pines y Pin-Board graphs o intereses de cada usuaro.
El artículo describe el sistema que Pinterest usa para su buscador, basado en embeddings, aprendido a partir de las interacciones de los usuarios.
El sistema utiliza una arquitectura de "dos torres" (two-tower). Hay dos redes neuronales separadas:
-
Torre de Consulta (Query Tower): Procesa la información del usuario (consultas, historial, etc.) y genera un embedding que representa al usuario.
-
Torre de Candidato (Candidate Tower): Procesa la información de los pines (imágenes, texto, etc.) y genera un embedding que representa al pin.
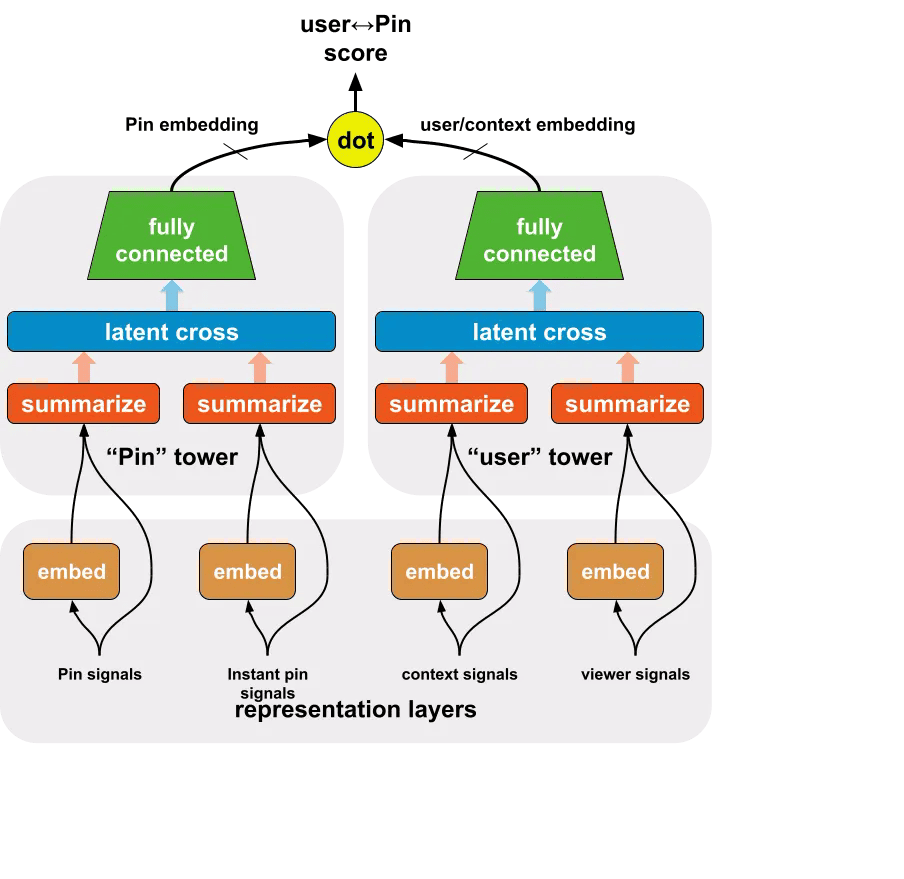
La similitud entre los embeddings del usuario y del pin se calcula (normalmente usando el producto escalar o la distancia coseno) para determinar la relevancia. El modelo se entrena con datos de interacción del usuario (clics, pins guardados, etc.).
Las partes principales del sistema son:
-
Generación de Candidatos (Learned Candidate Generation): Este es el componente central, que utiliza el modelo de dos torres para recuperar pines relevantes.
-
Entrenamiento Automatizado: El modelo se reentrena periódicamente con nuevos datos para mantener la precisión y adaptarse a los cambios en el comportamiento del usuario.
-
Sincronización de Versiones: Se asegura de que los artefactos del modelo (pesos, embeddings, etc.) estén sincronizados entre el entrenamiento y el servicio en producción.
-
Servicio en Producción: El sistema se implementa en el entorno de producción de Pinterest, atendiendo a millones de usuarios. Se integra con otros generadores de candidatos existentes.
El blog técnico de Pinterest está lleno de joyas, tiene artículos desde hace años mostrando y explicando cómo va mejorando su sistema de búsquedas, recomiendo bucear en su blog buscando las perlas que puedan ayudarte :)
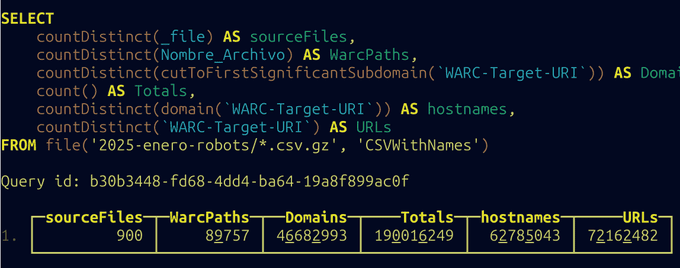
Procesado todos los robots.txt del último rastreo de Common Crawl
He obtenido todos los robots.txt procesados por CommonCrawl en el rastreo de Enero del 2025, estos son algunos datos curiosos:
Ver fuente original
- 72.162.482 robots.txt procesados
- 46.682.993 dominios
- 90.000 archivos WARC
- 500 GB