¿Cómo decide Google que URL debe rastrear?
Publicado el 2025-02-06 por Lino Uuñuela
Hasta hoy, cuando he hablado de indexación, crawl budget o políticas de indexación siempre he tenido como la mejor "fuente de la verdad" el artículo del 2018, escrito por BILL RICHOUX (Googler), "Crawling the internet: data science within a large engineering system".
El resumen podrá ser que, dadas unas restricciones, ya sean por verdades físicas (como que existen unos recursos limitados disponibles para el rastreo) y otras restricciones impuestas (por ejemplo, restricciones del robots.txt, estado del servidor, etc.), Google determinaba cuál es la URL con mayor probabilidad de haber sufrido un cambio significativo desde la última vez que fue rastreada.
Esto lo decidía en base a:
- PageRank o popularidad de la URL: no todas las URLs tienen la misma importancia, por lo que se ha de tener en cuenta esta importancia a la hora de ponderar cuál es la siguiente URL a rastrear.
- Probabilidad de haber sufrido cambios significativos desde el último rastreo.
- Restricciones: disponibilidad de los recursos de Google, restricciones impuestas (robots.txt, meta noindex, velocidad de carga) del servidor.
Hoy he descubierto este paper de Google (A Scalable Crawling Algorithm Utilizing Noisy Change-Indicating Signals) donde describe una mejora del método descrito en el artículo inicial.
El cambio principal es que añaden Señales que Incitan Cambios (Change Indicator Signals) a las ecuaciones para calcular cuál es la siguiente página que debe rastrear.
La idea es usar "señales" externas que avisan de que una página ha cambiado, antes de tener que rastrearla. Según el artículo, estas señales pueden venir de:
- Sitemaps: Archivos que los propios sitios web publican, listando sus páginas y cuándo se actualizaron por última vez.
- Redes de Distribución de Contenido (CDNs): Servidores especiales que ayudan a distribuir el contenido de las páginas web más rápido. Las CDNs saben cuándo cambia el contenido.
- Servidores web: Los propios servidores pueden enviar avisos.
Lo malo de estas señales (CIS) es que son "señales ruidosas" que generan falsos positivos (puede indicar que hubo un cambio significativo en la página pero en realidad no lo hubo, o el cambio que hubo no llega a ser un cambio significativo).
Las señales que Google recibe también generan falsos negativos (puede haber un cambio significativo y real, pero la señal no lo detecta) y, además, estas señales son de una calidad variable, donde algunas señales son muy fiables y otras no.
La mejora de este nuevo algoritmo respecto al anterior es que incorpora este modelo de ruido en la función de valor (crawl value function), calculando para cada página lo importante y/o urgente que es rastrearla en un momento dado.
Este depende de:
-
Cuánto tiempo ha pasado desde el último rastreo.
-
Cuántas señales CIS se han recibido (y su "peso" en términos de tiempo equivalente).
-
La probabilidad de que las señales sean verdaderas.
De esta manera, Google podría decidir rastrear una página no solo en función del tiempo transcurrido desde el último rastreo, sino también considerando la “información” (o ruido) aportada por las señales CIS.
Esto le permite a Google asignar de forma diferente los recursos disponibles, su crawl budget, dependiendo de si tiene muchas o pocas señales de una página:
- Páginas con muchas señales CIS (que pueden ser ruidosas) pueden ser rastreadas con menor frecuencia si se demuestra que la mayoría de dichas señales no corresponden a cambios reales.
- Páginas con pocas señales CIS (o con señales de alta calidad) recibirán más rastreos para mantener su contenido actualizado.
Pensando en SEO, podríamos llegar a la conclusión de que determinadas señales que nosotros mismos enviábamos con el objetivo de forzar a Google a indexar determinadas URLs podrían ser contraproducentes, ya que estaríamos enviando falsos positivos! (señales a URLs que no han sufrido modificaciones significativas), y a cada reintento degradamos la credibilidad de estas señales para nuestra página.
Juguemos a un juego...
Por 3 gallifantes, ¿qué señales son frecuentemente utilizadas por los SEOs para indicar a Google que rastree e indexe URLs? ...1,2,3 responda otra vez!
- "Los cambios de la fecha de última modificación en el sitemaps"
- "Los envíos de solicitud de indexación de URLs desde Google Search Console"
- "Añadir enlazado interno cuando ya tenía suficiente...."
-.... ¡Dejad vuestras respuestas!
Recomiendo su lectura, y cuando pensemos en temas que tengan que ver con el rastreo, crawl budget, frescura de contenido, etc., tengamos este artículo presente. No es que sea 100% de esta manera, porque no sabemos qué señales son, pero sí podemos intuir "por dónde van los tiros" a la hora de analizar determinado comportamiento en el rastreo o el impacto que tendrán los cambios que vamos a realizar
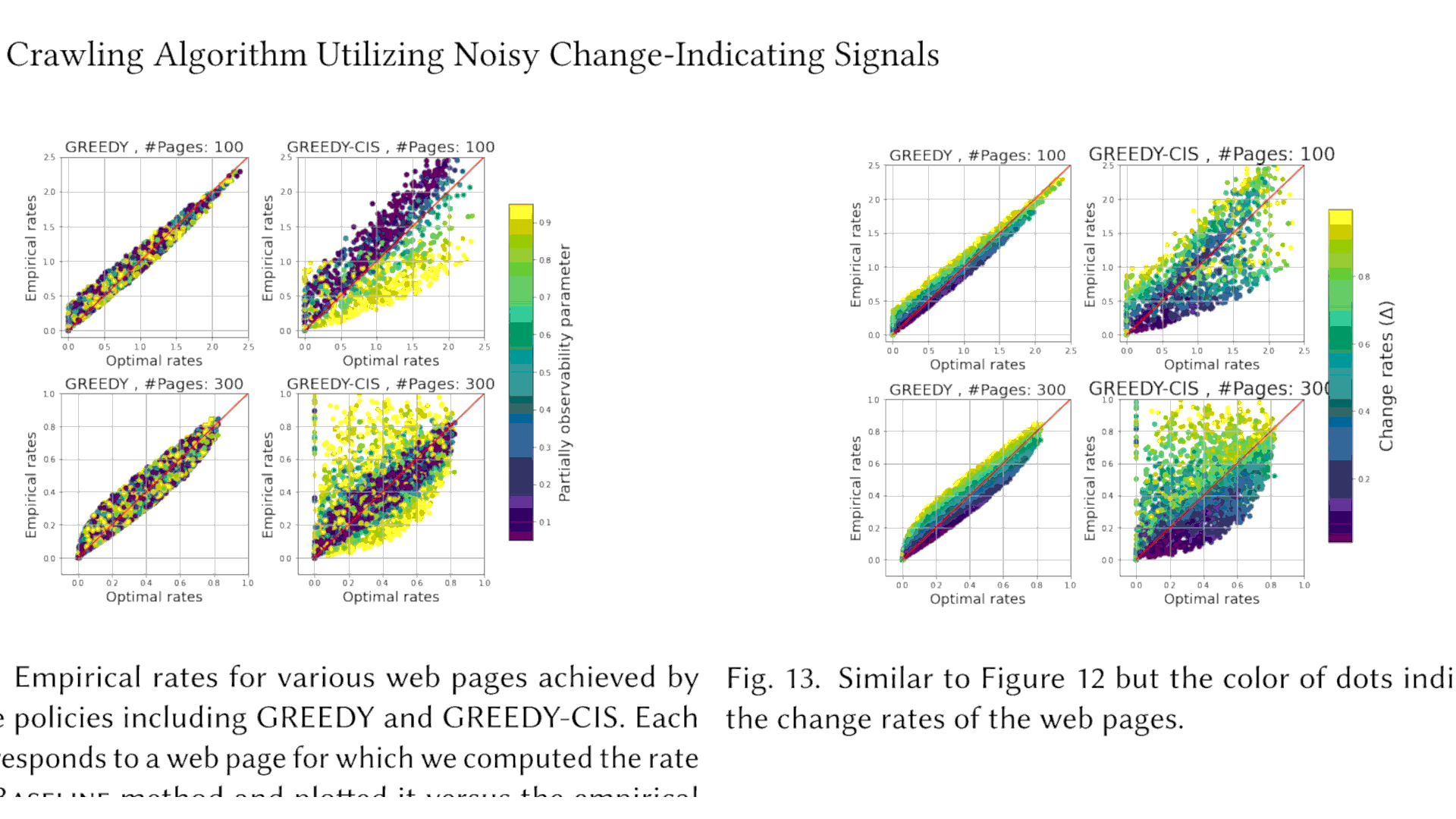
Tasas empíricas para varias páginas web logradas mediante políticas discretas, incluidas GREEDY y GREEDY-CIS. Cada punto corresponde a una página web para la que calculamos la tasa del método de línea base y la graficamos frente a la tasa empírica lograda mediante la política correspondiente. El color de los puntos indica la observabilidad de la secuencia de cambios que está controlada por la.

Lino (@errioxa)hace 71 días
Probando!
Lino2 (@linourunuela)hace 71 días
Hola
Lino2 (@linourunuela)hace 71 días
Hola @errioxa que tal
Juanan Carapapa (@carapapeando)hace 70 días
Yo también vengo a probar los comentarios, probando probando xD
Lino (@)hace 70 días
Funcionan!! Ahora solo tengo que generar engagement :D
A ver si quito lo de avisar por Twitter... no sé cuántos años llevará sin funcionar la API
Pedro (@)hace 70 días
1,2...1,2... probando.
Gracias por el artículo, verdaderamente interesante ver cómo no paramos de generar ruido :)
Lino (@errioxa)hace 70 días
3,2,1... Gracias a ti Pedro!! y sí, parece que los humanos somos expertos en haciendo ruido cuando intentamos que alguien nos escuche... :p
Alejandro (@spamloco)hace 67 días
Gracias Lino, siempre investigando un poco más allá.
Lino (@errioxa)hace 67 días
@spamloco a tí r hacerme ver que no soy al único que le importa :p
A ver si nos vemos!