Sistemas RAG avanzados, cuando la similitud no significa relevancia
Publicado por Lino Uruñuela el 25 de marzo del 2025 (2025-03-25)
Índice
Google anunció hace poco tiempo que añadirá una nueva pestaña llamada IA Mode. Las respuestas / resultados que se ven bajo esta nueva pestaña, según el propio Google, "se basa en nuestros sistemas de calidad y clasificación , y también utilizamos enfoques novedosos con las capacidades de razonamiento del modelo para mejorar la veracidad".
También nos da pistas sobre alguna de sus características como que "Utiliza una técnica de distribución de consultas, que genera múltiples búsquedas relacionadas simultáneamente en subtemas y múltiples fuentes de datos, y luego reúne esos resultados para ofrecer una respuesta fácil de entender".
Pero ¿qué significa esto realmente?. Para comprender mejor cómo podría funcionar un sistema como este, el cual permite la generación de Respuestas Aumentadas por Recuperación debemos hablar de Sistemas RAG.
¿Qué es un sistema RAG?
Un sistema RAG (por sus siglas en inglés, Retrieval-Augmented Generation), es una técnica que permite a los LLMs (Modelos de Lenguaje) generar una respuesta a partir de unos datos o documentos específicos que se le proporciona. De esta forma, puede ofrecer respuestas que no estaban en su conocimiento (datos que usó en su entrenamiento) minimizando el riesgo de alucinaciones o respuestas inexactas.
Los LLM a menudo no cuentan con la suficiente información sobre determinados temas, lo que les hace más propensos a cometer alucinaciones o devolver respuestas inexactas. Por ejemplo, si le preguntamos sobre noticias de actualidad o sobre los nuevos productos de tu empresa, no tendrá esta información y posiblemente la respuesta sea inexacta o incluso inventada.
Componentes de los Sistemas RAG
Un sistema RAG tiene dos componentes o subsistemas, un sistema de recuperación de información y un LLM.
El Buscador, o sistema de recuperación
Este sistema es el responsable de extraer fragmentos de información relevante desde una base de conocimiento como respuesta a una consulta determinada.
Esta base de conocimiento podría ser una lista de documentos concretos, por ejemplo los documentos PDFs de tu empresa, o una base de datos o, por ejemplo, un gráfico de conocimiento.
El Modelo de Lenguaje (LLM)
El papel del LLM es que recibe la consulta y la información devuelta por el sistema de recuperación como entrada para generar una salida (respuesta) basada en los resultados.
Los sistemas RAG tienen algunos pasos clave:
-
Indexación del corpus (o base de conocimiento). En este proceso se convierten los datos a embeddings que se almacenan en una base de datos vectorial.
-
Cuando un usuario realiza una consulta, el sistema de recuperación busca documentos relevantes en base a la consulta.
-
La consulta del usuario junto a los resultados devueltos se usan para crear un prompt.
-
El prompt se usa para indicar al LLM que genere una respuesta final.
Diferentes maneras de buscar información
Dentro de cada componente de un sistema RAG existen una variedad de posibilidades que podemos usar dependiendo del caso de uso. En este artículo vamos a profundizar sobre todo en el sistema de recuperación.
Recuperación Basada en Similitud Simple (Bi-Encoders)
Los sistemas de recuperación basados en una similitud simple (usando Bi-Encoders) son un método muy eficiente a la hora de obtener resultados desde una base de conocimiento con muchos elementos.
Los sistemas Bi-Encoders obtienen embeddings de tamaño fijo independientemente de la longitud del texto que procesan. El proceso para obtener los embeddings no requiere demasiados recursos y por ello podemos hacer una búsqueda sobre millones de documentos usando la distancia del coseno (u otras métricas para cálculos vectoriales) sin excesiva latencia.
Estos sistemas Bi-Encoders son modelos neuronales que transforman en embeddings el texto de la pregunta y el texto de la respuesta por separado.
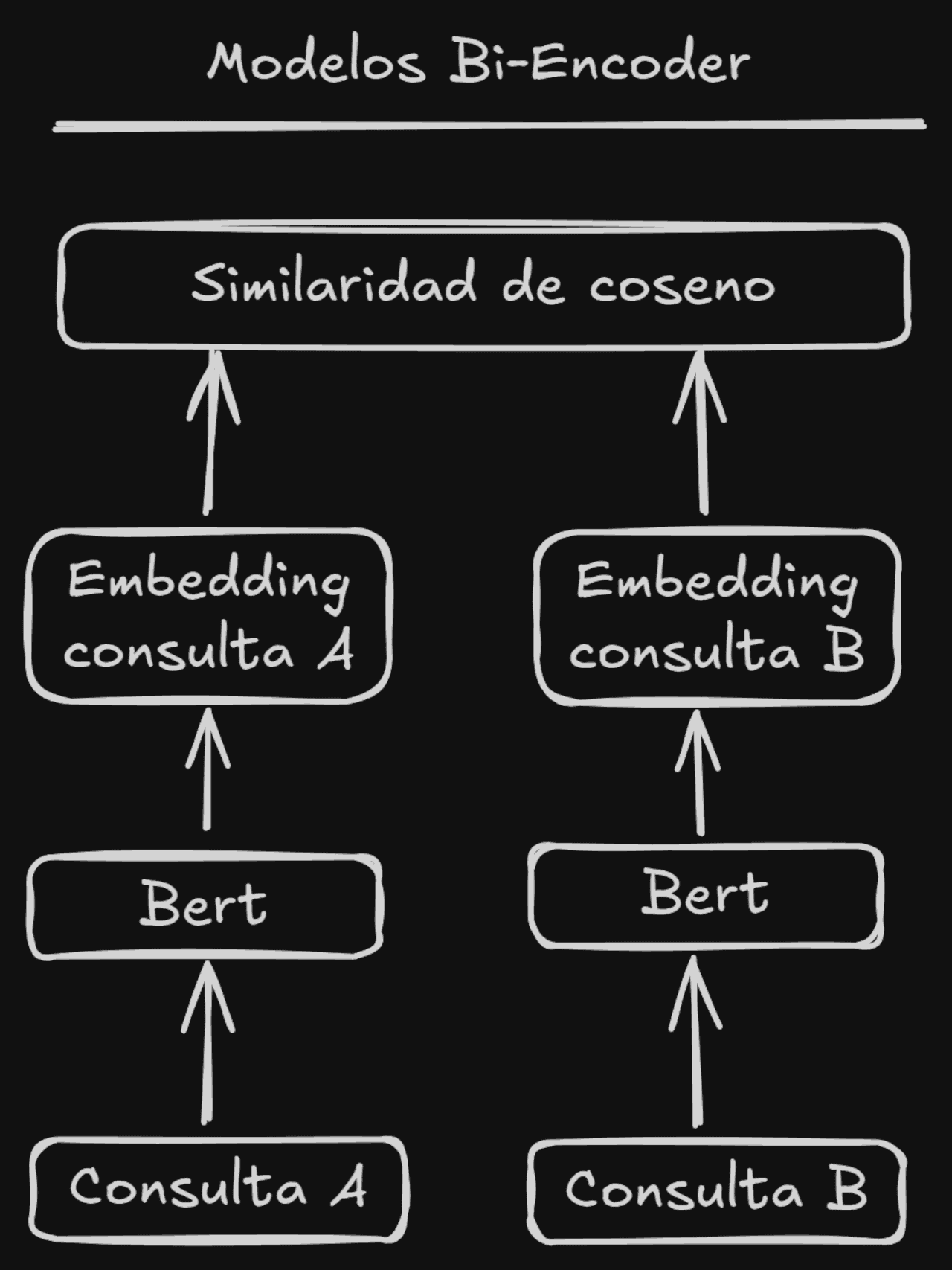
Los textos con significados similares estarán cerca en el espacio vectorial y captan las relaciones semánticas generales, pero muchas veces obtienen resultados que quizás no se ajusten a la respuesta esperada. Y es que se suele decir que la similitud no es lo mismo que la relevancia, como ejemplo típico, la pregunta "¿Por qué el cielo es azul?" tendrá un significado diferente a la respuesta, ya que una posible respuesta sería "La dispersión de la luz solar provoca el color azul.", el significado de esta respuesta es muy diferente (o muy poco similar) al texto de la consulta, algo que los SEOs deberíamos recordar muchas veces!
Para realizar una búsqueda en base a la similitud comparan el embedding de la consulta y el embedding de cada texto de todas las posibles respuestas, para realizar este cálculo se usan cálculos vectoriales como la distancia del coseno o la distancia euclidiana.
Este método es válido para tareas como la similitud semántica entre dos textos, la búsqueda semántica simple, la clusterización. También se usa en un primer paso de la recuperación de información avanzada (o sistema de recuperación de dos etapas), donde un modelo CrossEncoder (también conocido como re-ranker) se utiliza para re-ordenar una lista de resultados obtenidos por el Bi-Encoders.
Modelos Bi-Encoders habituales son:
- paraphrase-multilingual-MiniLM-L12-v2
- distiluse-base-multilingual-cased-v2
- paraphrase-multilingual-mpnet-base-v2
Otros modelos relevantes
- all-MiniLM-L6-v2
- modelos MS MARCO, idóneos para la búsqueda semántica asimétrica.
La ventaja de los Bi-Encoders frente a los Cross-Encoders es la escalabilidad y eficiencia si tienes un gran número de datos. Como los embeddings para la consulta y los embeddings de los resultados se generan de manera independiente, se pueden pre-procesar y guardar en una base de datos vectorial para que después se puedan realizar búsquedas con una baja latencia.
El hecho de que los embeddings de la búsqueda y los embeddings de los resultados se generen de manera independiente tiene sus desventajas, por ejemplo la pérdida de precisión a la hora de ofrecer resultados para consultas complejas o ambiguas. Esto hace que para las tareas en las que se requiere un análisis del contexto más avanzado puedan quedarse un poco cortos.
Recuperación Basada en Neural Matching (Cross-Encoders)
Estos sistemas, a diferencia de los Bi-Encoders, calculan la similitud dados un par de textos, es decir, procesan tanto la consulta como los textos del corpus a la vez.
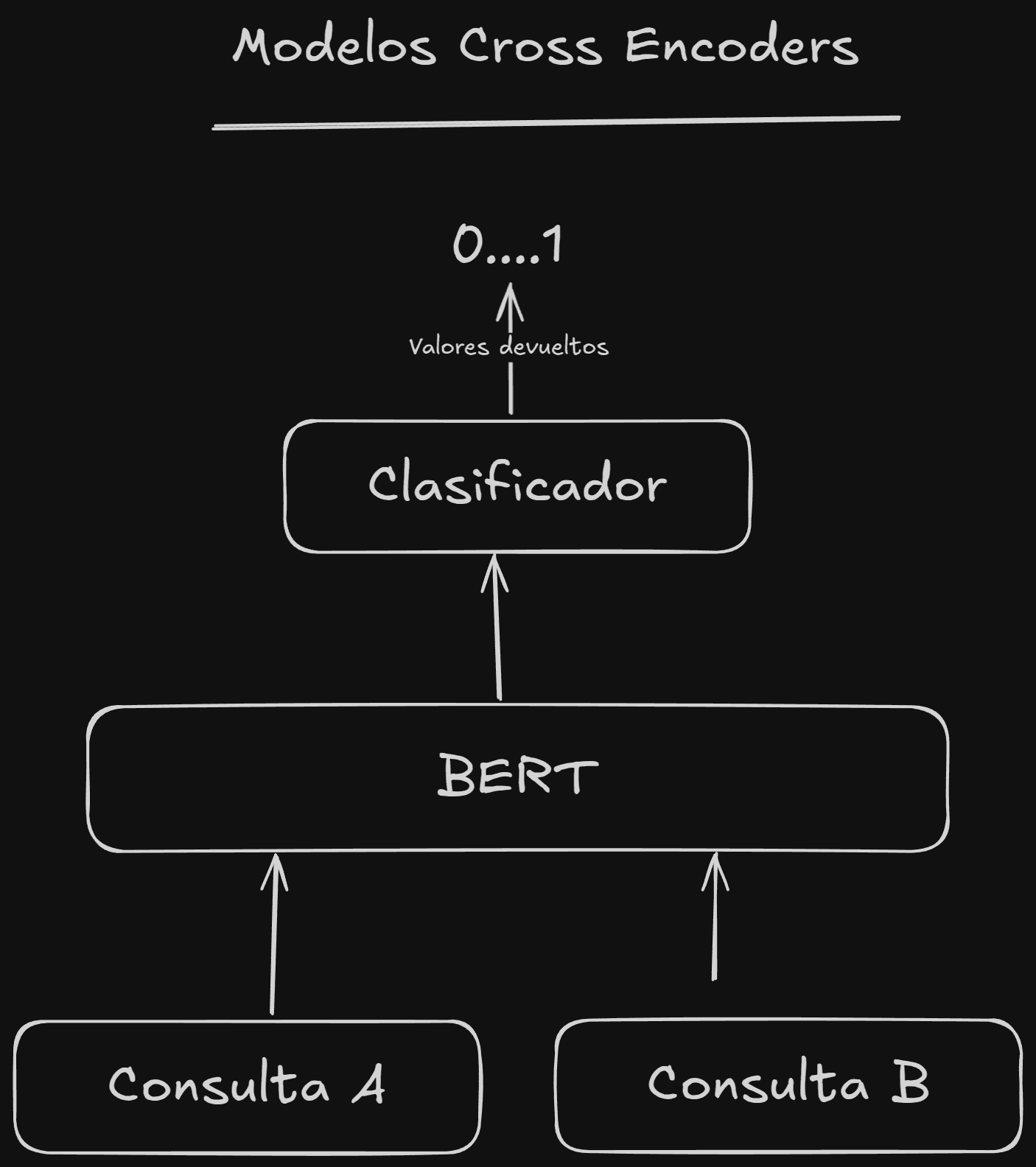
Esta capacidad de procesar la consulta y el documento a la vez les permite capturar relaciones y detalles semánticos mucho mejor y hace que comprendan mejor las intenciones de búsqueda en consultas ambiguas o complejas.
Lo malo de estos modelos es que son más lentos y requieren más recursos debido a que tienen que hacer los cálculos para cada par de textos (consulta-documento), lo que impide el pre-procesamiento y la indexación, ya que necesitaríamos por adelantado la consulta de búsqueda, pero no la tendremos hasta que el usuario realice la búsqueda...
Como no podemos guardar e indexar el cálculo para cada par consulta-documento, el coste computacional para realizar este cálculo aumentará con el tamaño del corpus. Es decir, si tienes que buscar en un montón de registros que forman el corpus en tu base de datos y luego obtener la relevancia para cada par consulta-documento, tardará mucho o requerirá mucha capacidad de procesamiento, tanto que muchas veces ni siquiera será posible o no será rentable, en términos de coste/beneficio, en comparación con otros métodos.
Por esta razón, los modelos Cross-Encoders normalmente se usan para reordenar (Re-Ranking) un número limitado de resultados obtenidos de la recuperación usando un modelo Bi-Encoders.
Existen una variedad de modelos Cross-Encoder preentrenados para diferentes tareas; por lo general estos modelos CrossEncoders son entrenados con el conjunto de datos MS MARCO:
- cross-encoder/ms-marco-MiniLM-L-6-v2 destaca en tareas de clasificación de pasajes.
- cross-encoder/stsb-roberta-base bueno para la similitud semántica.
Podemos decir que, en general, los Cross-Encoders son útiles para búsqueda por similitud semántica o el re-ranking (reordenamiento) de un pequeño número de documentos.
Bi-Encoders vs. Cross-Encoders ¿cuál es idóneo en un sistema RAG?
Como hemos visto, los Bi-Encoders son más rápidos que los Cross-Encoders, eso los hace más escalables y muy útiles en la primera etapa de recuperación, sobre todo cuando el número de documentos/textos donde buscar es muy elevado.
Los Cross-Encoders tienen una mayor precisión, pero requieren mucho más cómputo (y requisitos), por lo que son mucho más lentos; esta es la causa principal por la que no hace recomendable a los Cross-Encoders en la etapa inicial de la recuperación.
Tabla comparativa entre los diferentes métodos utilizados en un sistema RAG, Bi-Encoders y Cross-Encoders:
| Característica | Bi-Codificadores | Cross-Encoders |
|---|---|---|
| Procesamiento de Consulta y Documento | Procesados independientemente con dos codificadores separados. | Procesados simultáneamente con un único codificador. |
| Velocidad | Rápida debido a la codificación independiente y la búsqueda ANN. | Lenta debido al procesamiento por pares y la falta de indexación previa. |
| Precisión | Generalmente menor que los Cross-Encoders. | Generalmente mayor que los Bi-Codificadores. |
| Escalabilidad | Altamente escalable debido a la pre-computación de embeddings. | Menos escalable debido al procesamiento por pares. |
| Pre-computación de Embeddings | Posible para los documentos. | No posible. |
| Captura de Interacciones Detalladas | Limitada, ya que los textos se procesan por separado. | Alta, ya que considera la interacción entre los textos. |
| Casos de Uso Comunes en RAG | Recuperación inicial, búsqueda semántica a gran escala. | Re-clasificación de resultados recuperados, tareas de alta precisión. |
| Modelos de Ejemplo | paraphrase-multilingual-MiniLM-L12-v2, distiluse-base-multilingual-cased-v2. | cross-encoder/ms-marco-MiniLM-L-6-v2, cross-encoder/stsb-roberta-base. |
Lo idóneo es usar un método híbrido, con un Bi-Encoder en la primera etapa que devuelva un número limitado de candidatos y usar en la segunda etapa un Cross-Encoder para reordenar estos candidatos.
Búsqueda Simétrica vs. Asimétrica
Algo que debemos tener muy en cuenta es si en nuestro caso de uso debe realizarse una búsqueda simétrica o asimétrica, ya que esto definirá qué modelo deberíamos utilizar para obtener los embeddings y también definirá cuál será la estrategia de recuperación adecuada.
Búsqueda simétrica
En la búsqueda simétrica la principal característica es que la longitud de la consulta y el resultado son parecidas. Por ejemplo, la consulta "¿Cómo aprender SEO online?" podría devolver resultados como "¿Cómo aprender SEO en internet?".
La búsqueda simétrica es útil para identificar el contenido duplicado de títulos o párrafos muy similares. Un "truco" para saber si nuestra búsqueda es simétrica es pensar si cambiando el orden de la consulta y la respuesta alteraría el resultado y/o la relación semántica entre ellos.
Búsqueda asimétrica
En la búsqueda asimétrica la longitud de la consulta suele ser mucho menor que la longitud de la respuesta (por ejemplo, un párrafo).
Este tipo de búsqueda es el que deberíamos usar si queremos un sistema de pregunta-respuesta o chats, ya que dada una consulta muy concreta se desea encontrar una respuesta que normalmente es más detallada.
Búsqueda en dos etapas: Recuperación y Reordenación
Los sistemas de búsqueda semántica más avanzados en la actualidad utilizan un sistema de dos etapas:
Etapa de recuperación
El objetivo en esta etapa es devolver un número limitado de resultados (ya sean documentos o fragmentos de texto) que son potencialmente relevantes para la consulta.
En esta etapa de recuperación se utilizan diversas técnicas para ampliar el alcance o cobertura. Por ejemplo, se combinan la búsqueda por coincidencia de palabra clave (algoritmos como BM25), con la búsqueda semántica y con la búsqueda aumentada para obtener un conjunto de resultados intentando no dejarse documentos potencialmente relevantes en el camino.
Es aquí dónde también entra una técnica denominada expansión o distribución de consultas. Esta técnica puede usar diversos métodos para que dada una consulta inicial, obtener otras consultas equivalentes de manera que cubran diferentes términos o contextos relacionados conceptualmente, y suena muy similar a la técnica que dice Google usar para IA-Mode!.
Pero seguramene Google usa métodos más afinados, por ejemplo escribí no hace mucho Cómo selecciona Google el fragmento que responde a una pregunta, dónde explico el método que podría utlizar basándome en una patente reciente de Google
Dejo un fragmento del artículo que nos da una idea aproximada:
Embeddings y similitud del fragmento con la consulta del usuario
Una vez que Google recupera un conjunto inicial de documentos relevantes, por ejemplo, los "Top 10,000", el siguiente paso es buscar el fragmento exacto de texto que mejor responde a tu consulta. Para ello, Google parece realizar los siguientes pasos:
- Generación de Embeddings de la Consulta: Primero, Google convierte tu consulta en un vector de embeddings.
- Comparación de Similitud: Luego, compara este vector con los embeddings de fragmentos de cada uno de los documentos recuperados para encontrar el que más se asemeje.
- Consideración de la Jerarquía de Encabezados: Google también tiene en cuenta la similitud/cercanía de cada fragmento candidato con sus encabezados (H1, H2, H3, etc.) superiores jerárquicamente. Posiblemente "sume" la similitud que hay entre el fragmento candidato y la concatenación de los Hx que están jerárquicamente en su nivel superior inmediato hasta llegar al título.
Ir al artículo ¿Cómo selecciona Google el fragmento que responde a una pregunta?
Pero incluso usando estas técnicas para mejorar las consultas podrían generar resultados que no son tan relevantes como quisiéramos, por ejemplo, para un sistema de preguntas y respuestas el resultado puede que sea similar a la pregunta pero que no ofrezca respuesta a la pregunta; es en este tipo de casos cuando debemos recordar que la similitud no es lo mismo que la relevancia.
Etapa de reordenación
Para mejorar los resultados obtenidos en la etapa de recuperación se puede aplicar una segunda reordenación de los resultados devueltos (Re-Ranking).
Los candidatos obtenidos en la etapa de recuperación son pasados a un modelo Cross-Encoder junto a la consulta; esto genera una puntuación entre 0 y 1 que indica la relevancia del documento para la consulta.
La principal ventaja de utilizar Cross-Encoders en esta etapa es su capacidad para prestar atención tanto a la consulta como al documento de forma conjunta. Los modelos Cross-Encoders capturan las relaciones de contexto y los detalles semánticos, algo que los Bi-Encoders podrían no hacer.
Otras técnicas útiles para RAG
Además de lo que hemos visto, que digamos, son las técnicas básicas de los RAGs actuales, existen otras técnicas que mejoran o complementan a estas.
Por ejemplo, cómo dividas el texto de un documento en párrafos o frases es también vital para el funcionamiento del sistema.
Otra técnica, o caso aparte, sería la integración del sistema RAG con un gráfico de conocimiento que permita al sistema comprender las conexiones y poder responder a preguntas que requieren varios saltos o cadenas de pensamiento.
Usar LLM para generar la respuesta
Como último paso en el sistema de RAG, le indicaremos al LLM que usemos que genere la respuesta en base únicamente a los resultados devueltos por el sistema de recuperación. Dependiendo de nuestro objetivo y del LLM, generaremos un prompt adecuado para que responda como queremos. ¡Incluso podríamos decirle que vuelva a ordenar los resultados!
En próximos artículos intentaré explicar qué es la búsqueda del vecino más cercano, índices aproximados de vecinos más cercanos y cómo estos índices también son cruciales para llevar un sistema RAG a producción.
