Notas semanales 5
Publicado el 2025-01-31 por Lino Uuñuela
El buscador de Google requiere JavaScript
Desde hace un par de semanas Google ha dejado de mostrar resultados si el navegador no tiene habilitado JavaScript.
A primera vista parece algo sin importancia porque casi todo el mundo accede a internet utilizando navegadores con JavaScript habilitado, según el propio Google el 99,9 %..
En promedio, “menos del 0,1 %” de las búsquedas en Google las realizan personas que desactivan JavaScript
Ver fuente original (Techcrunch)
Habilitar JavaScript nos permite proteger mejor nuestros servicios y usuarios de bots y formas cambiantes de abuso y spam.
Ver fuente original (Techcrunch)
Por supuesto, no ha sido la única medida que ha tomado para impedir a estos rastreadores obtener los resultados, también ha añadido otras medidas cómo la detección de comportamientos extraños o sospechosos ya que si realizas unas cuantas peticiiones seguidas rápidamente saltará el captcha....
Llevo más de una década monitorizando miles de KWs diarias, tengo literalmente Terabytes de pantallazos de búsquedas de Google, y tendré que revisar mi crawler para adaptarlo ya que accedía sin habilitar JavaScript pero eso ya no funciona :p.
Aquí os dejo un vídeo que hice hace años, un timelapse de dos años de pantallazos
El tener que acceder con javascript habilitado no supone un desafío tecnológico, hoy en día es fácil montar un script que se comporte como un navegador que ejecute ciertos comandos de JavaScript, el problema radica en el aumento del costo de procesmiento, el coste puede ser un x10 en cada búsqueda monitorizada, y eso llevado a escala es muchísimo dinero, ¿veremos aumento de precios en herramientas de monitorización de KWs?... el tiempo lo dirá
Consigue que los visitantes sigan interactuando con la recirculación - Google News Initiative
El artículo / lección de Google News Initiative ofrece algunos datos curiosos y diferentes recomendaciones para medios de comunicación y periodistas.
Actualmente, hay más usuarios que acceden a las noticias digitales a través de las redes sociales (28 %) que directamente a través de sitios y aplicaciones de noticias (23 %).
Ver fuente original
En una lección titulada "Mantén el interés de los visitantes" para mejorar la "recirculación" de usuarios nos sugiere añadir una sección de artículos recomendados en un sitio web, con el objetivo de mantener a los visitantes más comprometidos. Las recomendaciones se centran en la facilidad de lectura y la presentación clara. Me llamó la atención la concreción en algunos aspectos sobre los "artículos relacionados" que recomienda añadir a cada artículo; "hasta cinco artículos"
Haz que tu sección de artículos recomendados sea fácil de leer
Prácticas recomendadas:
- Recomienda hasta cinco noticias
- Incluye una imagen en todos los artículos
- Coloca las imágenes a la izquierda y las noticias a la derecha
- Comprime las imágenes
- Clasifica los artículos
Ver fuente original
También sugiere añadir una sección fija, que se vea en todo el sute, y que esté "encima de los enlaces externos"
Recomienda artículos en todo tu sitio:
- Coloca tus artículos encima de los enlaces externos
- Añade una sección de artículos recomendados después de cada artículo
- Ancla una sección de artículos recomendados a la derecha
- Añade un artículo recomendado con una imagen relacionada en todos los artículos
Ver fuente original
Introducción a ModernBERT – Answer.AI
Answer.AI publicó un Bert mejorado o moderno, ModernBERT.. (disponible en Huggingface)
Una de las nejoras más notables es la mayor longitud de contexto, que aumenta de 512 a 8192 tokens
Dependiendo de qué tarea vayas a realizar puedes elegir entre una variedad de modelos, todos con sus pros y sus contras...
Para tareas como la búsqueda vecotorial o la recuperación aumentada (RAG) el límite de 512 tokens en la longitud de contexto es algo bastante limitante, mejoras como la que puede traer ModernBERT pueden ser, a priori, muy significativas.
Un contexto pequeño a menudo hace que para guardar la información de un documento o un artículo teníans que trozcearlo en frases / párrafos y muchas veces los fragmentos tan pequños no son capaces de captar todo el significado y la relación con los párrafos adyacentes, motivo por el que pierde calidad en este tipo de tareas.
Además, la cantidad de fragmentos totales que deberás almacenar también puede ser de órdenes mayor lo que te puede complicar la vida...
SiteOne Crawler
Crawler de código abierto, escrito en C++ (lo que lo hace muy rápido), tiene miy buena pinta para rastrear aquelas webs ENORMES dónde nuestra ranita preferida (Screaming Frog) no llega.
Ofrece múltiples interfaces: aplicación de escritorio, línea de comandos o simplemente generando reportes en formato HTML.
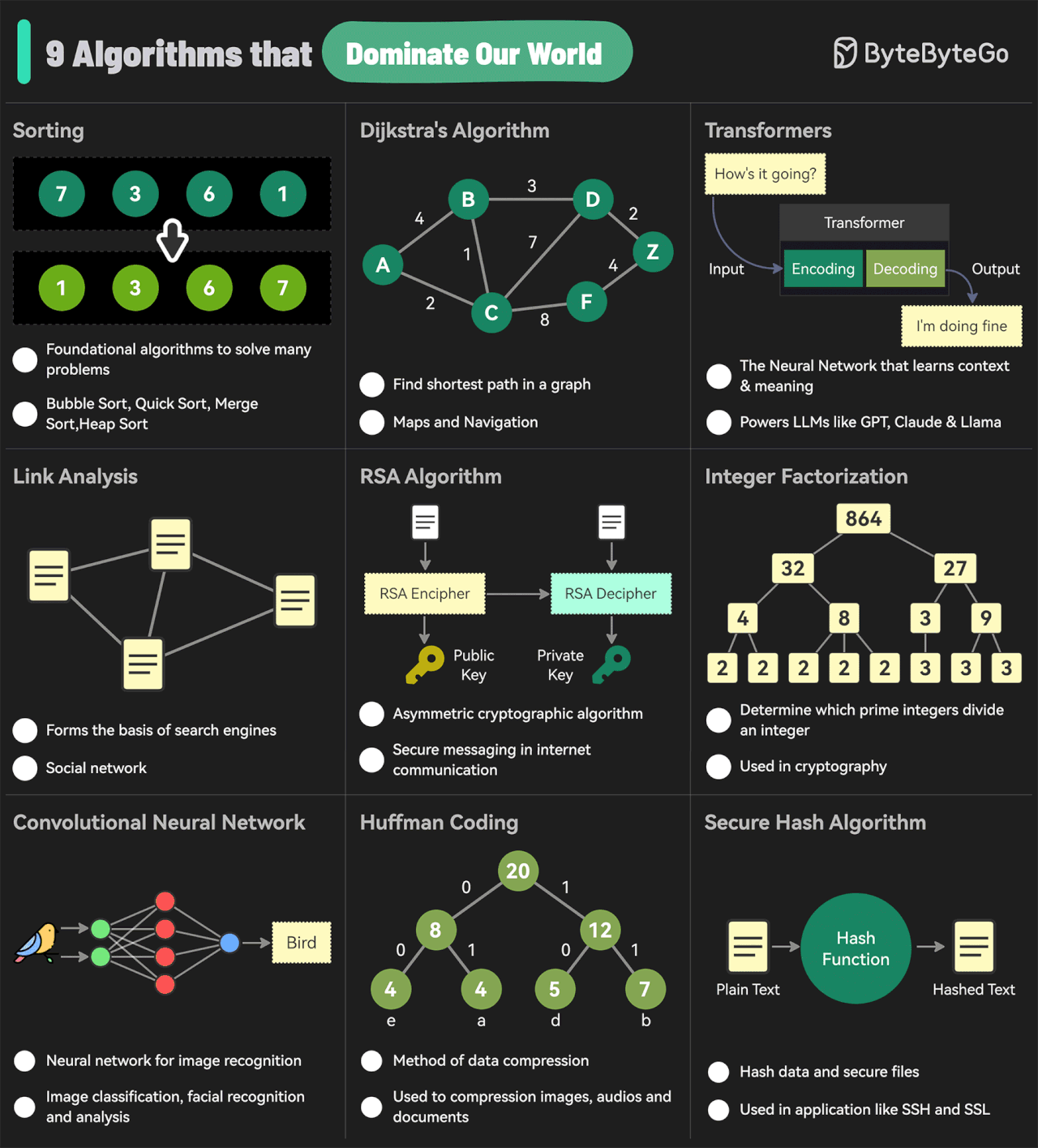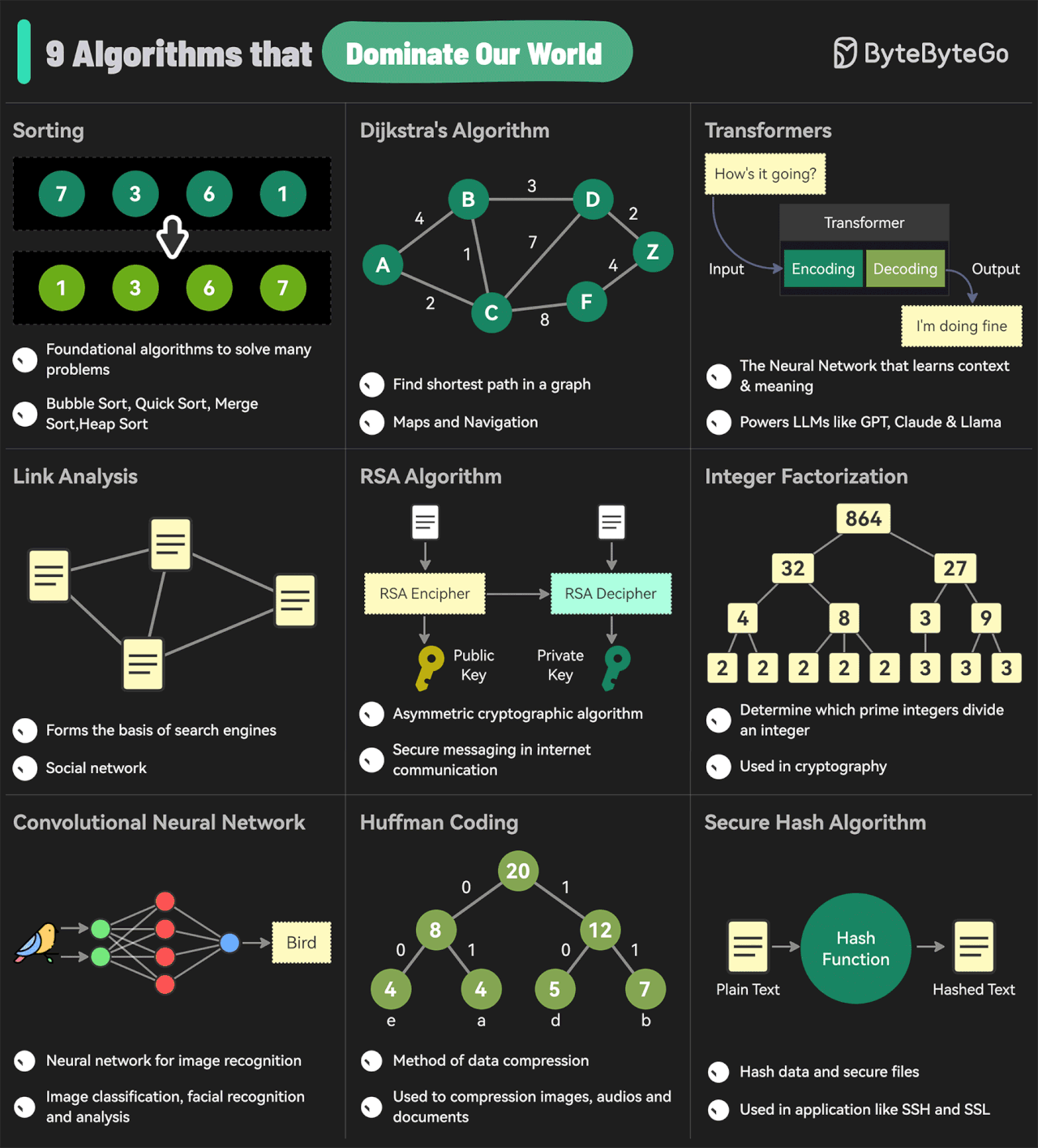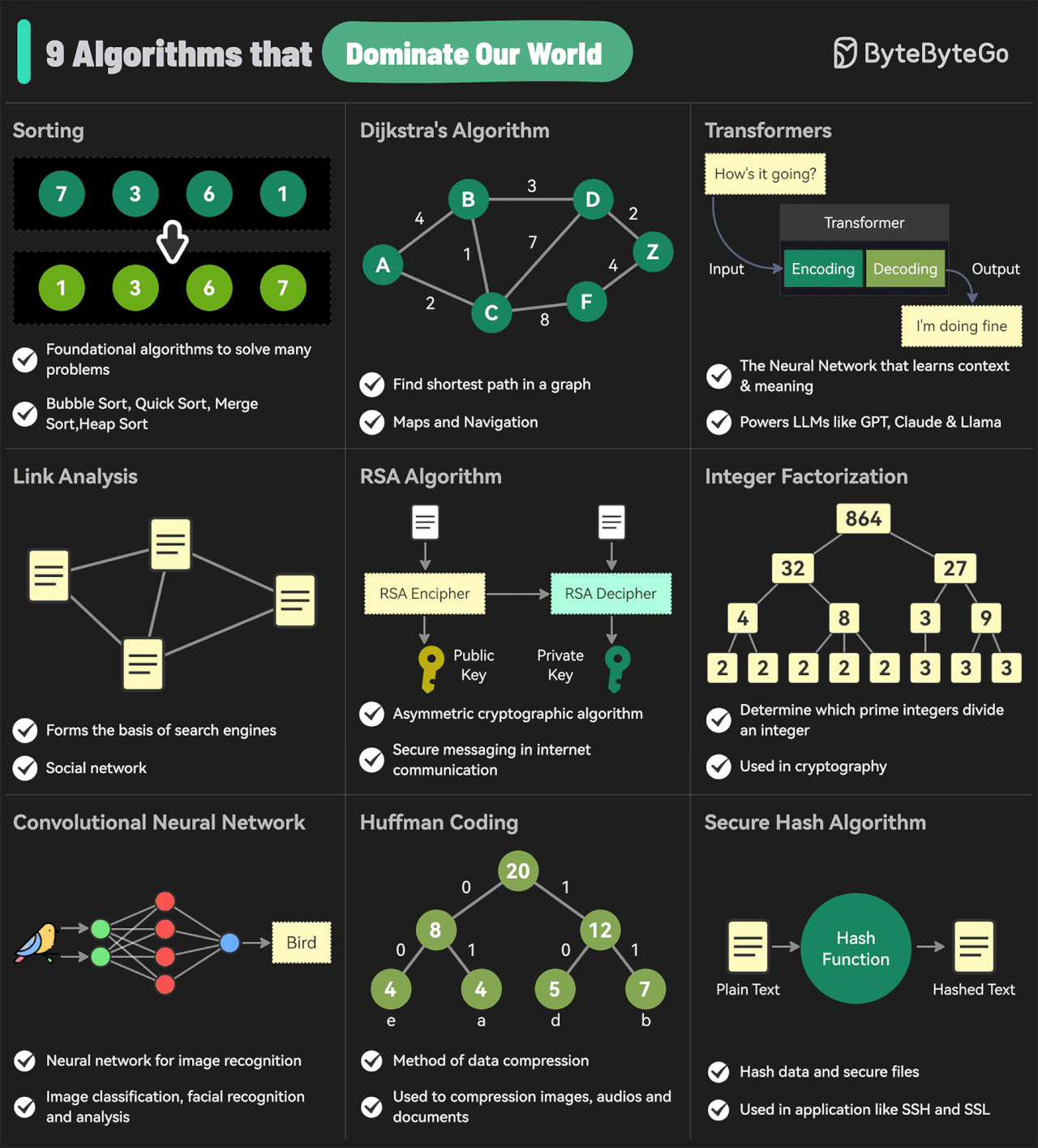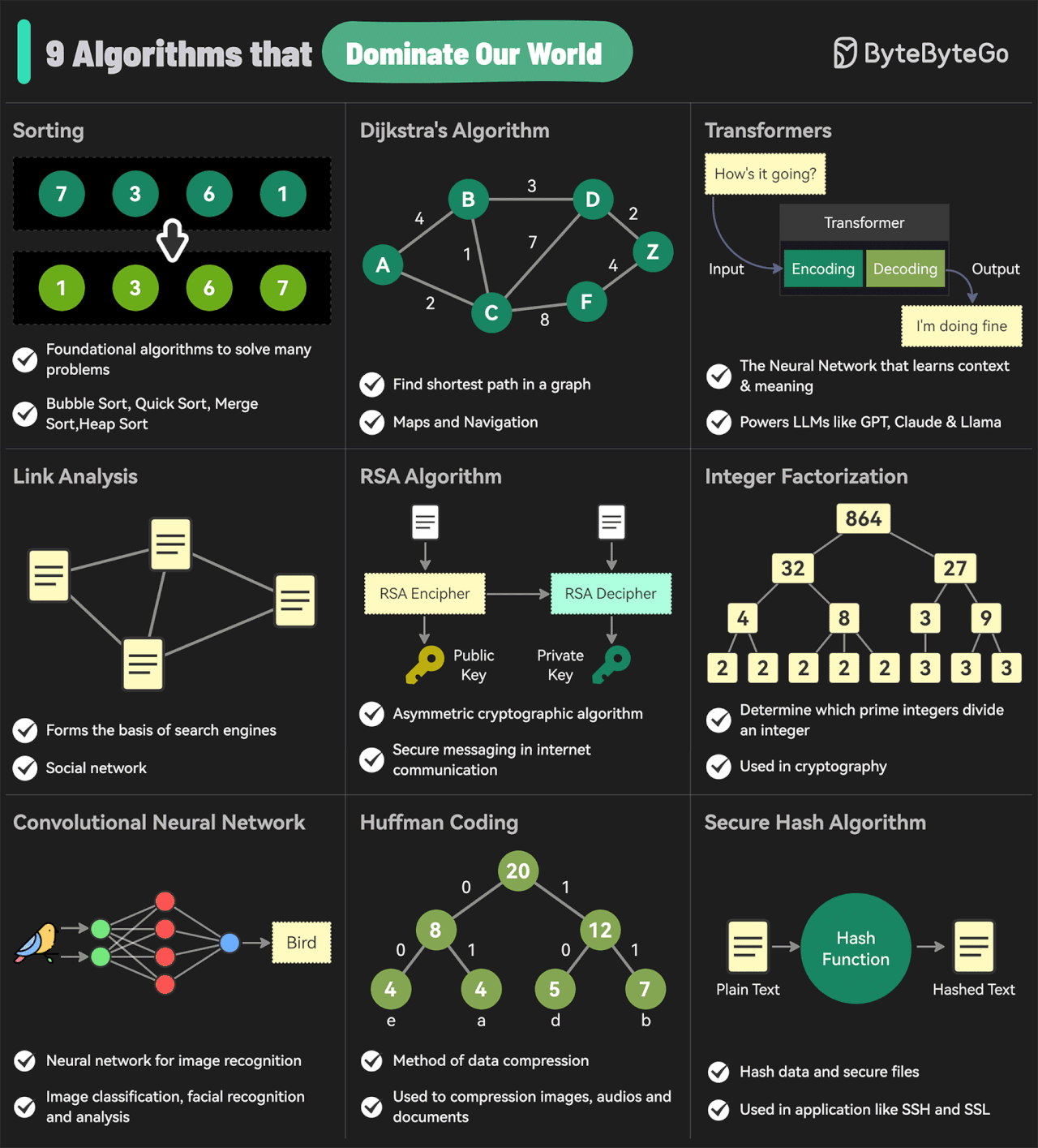
EP144: The 9 Algorithms That Dominate Our World
Me resultó curiosa esta imagen de algunos de los algoritmos más influyentes que dominan el mundo actual
Sam Altman en X
... estamos perdiendo dinero en suscripciones a Openai Pro!. La gente lo usa mucho más de lo que esperábamos.[...] ..no, yo personalmente elegí el precio y pensé que ganaríamos algo de dinero./a>
Ver fuente original
Deliberation in Latent Space via Differentiable Cache Augmentation
Este paper de DeepMind propone un método para mejorar el rendimiento de los LLMs sin modificar sus pesos.
Un coprocesador inyecta tokens latentes en la caché mejorando los resultados en tareas de razonamiento y una menor perplejidad.
demostramos que un LLM congelado se puede ampliar con un coprocesador fuera de línea que opera en el caché de clave-valor (kv) del modelo
Ver fuente original
- Utiliza el caché de clave-valor del modelo para mejorar su rendimiento.
- Evita la modificación directa de los parámetros del LLM.
- Permite mantener la estabilidad del modelo, al mismo tiempo que se amplía su capacidad.
Dario Amodei — CEO de Anthropic - Sobre DeepSeek
Hubo mejoras [sobre DeepSeek] particularmente innovadoras en la gestión de un aspecto llamado "caché de clave-valor" y en permitir que un método llamado "mezcla de expertos" se llevara más lejos de lo que se había hecho antes,
Claude 3.5 Sonnet es un modelo de tamaño mediano que costó unos pocos decenas de millones de dólares entrenar
Ver fuente original
ALIA: el LLM español
Charla dónde uno de los responsables (Autor Gonzalex Aguirre) del LLM español, ALIA, habla sobre los conjuntos de datos utilizados, características del súper-ordenador (el Marenostrum 5) con el que se entrena, la existencia de diferemtes versiones / tamaños del modelo (2B y 7B, y 40B)
Common Crawl - Blog - Introducing cc-downloader
Common Crawl desarrolla cc-downloader, una herramienta de línea de comandos escrita en Rust para facilitar y mejorar la descarga de datos de Common Crawl.
Ya os contaré que tal va porque tenog un proyecto en mente para el que sin duda me vendrá de perlas :)
