Notas de la semana 47
Publicado el 2024-11-22 por Lino Uruñuela
Hoy comienzo una nueva sección a la que de momento la llamaré 'Notas semanales' dónde iré publicando, eso, mis notas semanales. No esperéis artículos elaborados u súper refinados, al contrario, esta sección serán notas, piezas de código, comentarios de otras personas que he ido apuntando, en definitiva, cosas que he haya ido haciendo durante la semana y que crea que a otras personas les pueda ser útil. Sin más preámbulos vamos con la primera
Marcador para ver artículos de pago
Hay ocasiones en que llegamos a algún artículo por el que tenemos mucho interés y nos llevamos una decepción porque el acceso al texto completo solo está disponible para suscriptores. Por ejemplo, si quieres leer algún artículo de medios como el The Wall Street Journal.
Un día di con un sitio al que le pasas la URL y la mayoría de las veces te ofrece una URL donde se encuentra el texto completo... no me preguntéis de dónde ha salido el sitio, no lo he investigado, pero me encanta.
Para agilizar el proceso cuando doy con un artículo para suscriptores, he creado un código JavaScript que, al añadirlo a tu barra de marcadores como si fuese una URL normal, te llevará directamente a la búsqueda en Archive.ph de la URL en la que estés (la del artículo para suscriptores). Luego solo tienes que hacer clic en el enlace que muestra y voilà.
Código JavaScript que debes añadir a tu barra de marcadores
javascript:(function () { window.location.href = 'https://archive.is/' + window.location.href.replace(/\?.*$/, '').replace(/#.*$/, '');})();
Nueva Extensión
Google Search Results Number
Está claro que el mundo se ha empeñado en fastidiarme con pequeños detalles. Esta vez es Google el que oculta un pequeño fragmento de texto que muchas veces nos interesa ver rápidamente: el número de resultados que tiene Google para una determinada búsqueda.
No ha eliminado esa información, pero sí dificulta que veamos ese dato, ya que actualmente, para ver el número de resultados, hay que hacer clic en el botón de "Herramientas" para verlo.
La extensión Google Search Results Number hace precisamente eso, mostrar automáticamente el número de resultados de cada búsqueda.
Extensiones actualizadas
Esta semana he actualizado algunas extensiones que estaban usando la versión 2 de manifest.js y que pronto dejará de funcionar.
Show Published Date
A veces te interesa saber hace cuánto se escribió lo que estás leyendo, sobre todo si son temas donde la fecha podría ser muy relevante. Muchos blogs ocultan la fecha de creación o de actualización de sus artículos, deduzco que precisamente porque son antiguos y piensan que es mejor ocultar la "edad" del contenido...
Así que creé la extensión Show Published Date que, al hacer clic en el icono, busca la fecha usando diferentes patrones, metadatos o datos estructurados, y si la encuentra, la muestra. No siempre lo consigue, pero la tasa de "aciertos" ha hecho de esta extensión una de las que más utilizo.
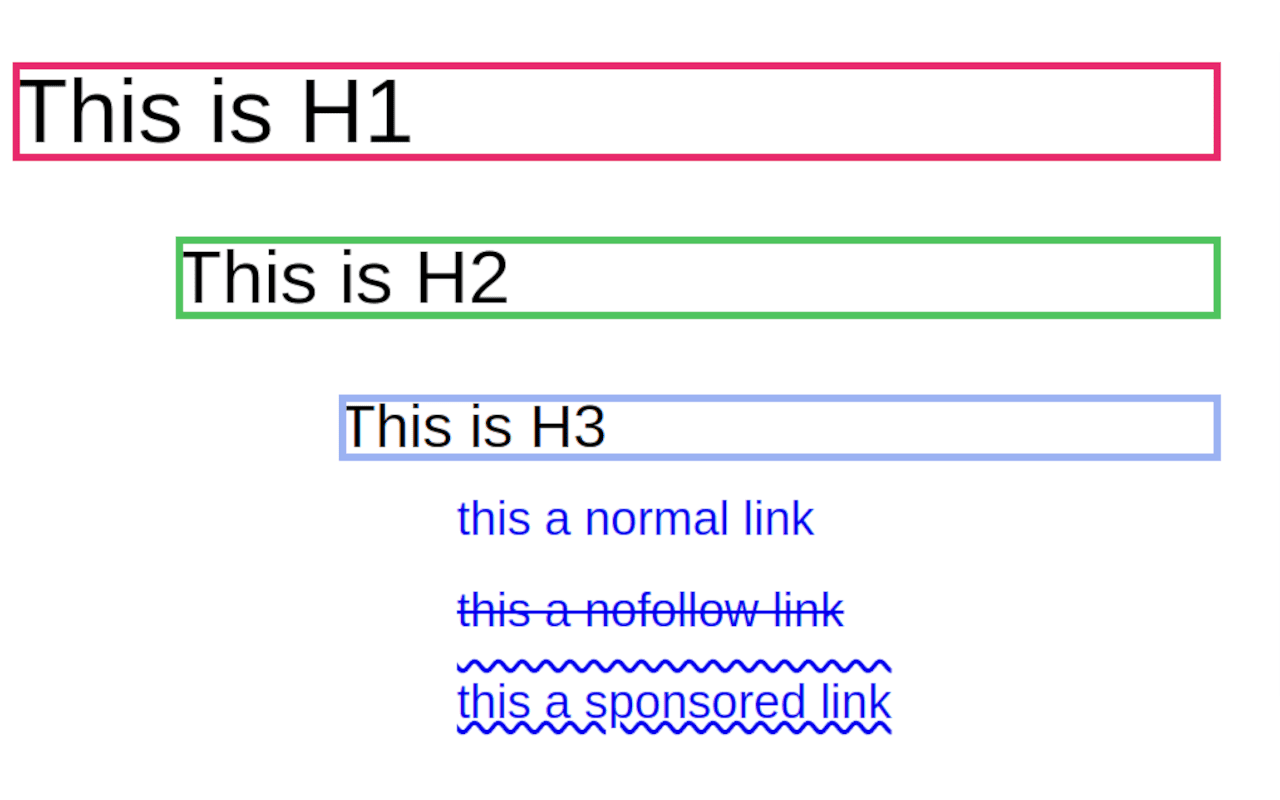
Highlight H1 and nofollow, sponsored & ugc
Esta extensión también estaba desarrollada bajo la versión 2 de manifest y que gracias a Claude y ChatGPT he actualizado en un momento.
Highlight H1 and nofollow, sponsored & ugc resalta los H1, H2, H3 y H4 cuando haces clic en el icono de la extensión. Resaltará los Hx añadiendo un borde de color rojo para el H1, verde para H2, amarillo para H3, etc. También resalta los enlaces "nofollow", "sponsored" y "ugc" tachando esos enlaces de diferentes maneras.
Citas y Lecturas interesantes
- Docling, herramienta que extrae el texto de documentos PDF, DOCX, PPTX, XLSX, imágenes, HTML, AsciiDoc y Markdown y exporta a Markdown y JSON. No la he probado, pero tiene buena pinta. Me gusta la idea de que, por ejemplo, para extraer la información de documentos PDF, usa OCR (reconocimiento de texto en imágenes). Quien se haya enfrentado a la extracción de información a partir de documentos PDF sabe de lo que hablo. Para los que no, aunque existen una gran variedad de programas o scripts que extraen el texto de PDFs, es sencillo si solamente quieres el texto plano, lo cual no es útil en muchas ocasiones. Además, muchos PDFs han sido convertidos o creados a partir de una imagen (por ejemplo, las patentes) y en estos casos no podremos extraer la información en el PDF. Por eso quiero probar Docling; cuando lo haga, os diré qué tal ha funcionado.
- Listening To The Algorithm
"La capacidad de traducir o resumir es una de esas capacidades extremas que pueden confundir más que aclarar las cosas en el contexto de los debates sobre la 'inteligencia artificial general'"
- Alex Albert en Twitter
"Hasta hoy, cuando adjuntabas un PDF en Claude Dot Ai, utilizábamos un servicio de extracción de texto para capturar el texto y enviárselo a Claude en el mensaje. Ahora, Claude puede ver el PDF visualmente junto con el texto.'"
- Ask a Techspert: What's the difference between a CPU, GPU and TPU?
"Si cada usuario comenzara a “hablar” con Google durante solo tres minutos al día, necesitaríamos duplicar el número de computadoras en nuestros centros de datos."
