La segunda ola de indexación y cómo saber qué renderiza Google
Publicado por Lino Uruñuela el 23 de julio del 2018
Desde hace ya unos años venimos viendo cómo Google es capaz de cargar e indexar ciertos contenidos via javascript, en este blog hemos hecho muchos experimentos sobre cómo Google rastrea e indexa el contenido cargado mediante
JavaScript.
Los últimos experimentos sobre Google e indexación de javascript fueron encaminados a intentar
saber si
Google era capaz de ejecutar funciones javascript "complejas" y si
era capaz de acceder e indexar el contenido cargado mediante llamadas
Ajax y hemos comprobado cómo Google accedía e indexaba estos contenidos por muy ofuscados que hiciéramos esas llamadas JavaScript, siempre y cuándo este código se ejecutara automáticamente sin interacción del usuario, por ejemplo en contenido cargado en el onReady o onLoad
Los resultados y las conclusiones de este experimento los podéis ver con más detalle en este post sobre cómo ejecuta, rastrea e indexa el contenido cargado mediante javascript.
A tener en cuenta: cuando hablo de JavaScript hablo de las versiones compatibles con Google Chrome 41, que no es totalmente compativle con la versión ECMAScript 6 de JavaScrtipt
Analizando cuándo y qué urls renderiza Google
Cuando analizamos los logs del servidor generados por Google podemos
observar algo muy importante, y que a todos se nos había pasado por
alto, cuándo Google carga recursos como ficheros javaScript, hojas de estilo css o urls de contenido cargadas mediante ajax en todos estos casos lleva en el campo referer la url de origen, y esta es la url que está siendo renderizada!.
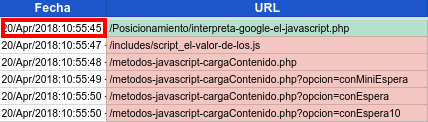
En este ejemplo podemos ver en el campo "URL" la URL de origen, con fondo verde, /Posicionamiento/interpreta-google-el-javascript.php, y en rojo las urls de contenido cargadas por javascript como por ejemplo /metodos-javascript-cargaContenido.php y también urls de hojas de estilos css o urls de recursos js.

No me había dado cuenta de la importancia de esto hasta que escuché la famosa presentación que Tom Greenaway y John Mueller dieron en el Google I/O de este 2018, dónde explicó cómo Google procesa los contenidos cargados mediante javascript.
Resumiendo podemos decir que Google procesa el contenido de una url en dos procesos / fases / olas. En una primera ola Google funciona cómo siempre lo hemos entendido.
Primera ola de indexación
- Accede a la url que tiene en su lista de urls a rastrear.
- Obtiene el HTML de esa url, sin ejecutar JavaScript. Es lo que vemos cuándo le damos al botón dercho del ratón y seleccionamos "Ver código fuente de la página").
- Evalua en base a multitud de variables ese HTML obtenido y decide si la indexa y qué imporancia da al contenido de esa url.
Pero John Mueller nos aclaró un tema muy importante, si en la url a la que accede Googlebot se carga contenido mediante javascript, Google volverá a acceder a esa url cuándo tenga recursos disponibles, y esta vez renderizando el DOM y ejecutando JavaScript, concretamente el navegador Chrome41, a esto lo ha denominado "la segunda ola".
En esta segunda ola Google realizará los siguientes pasos
Segunda ola de indexación
- Accede a la url que tiene en su "lista de espera" por renderizar
- Obtiene el HTML de esa url.
- Evalua en base a multitud de variables el HTML de la url de origen renderizado, es decir evaluará el contenido y recursos cargados en la rederización
Esta gran pista me sirvió de inspiración... ¡eureka!, me di cuenta de que muchos de los resultados que estábamos viendo en los experimentos con JavaScript antes mencionados se podrían explicar perfectamente si tenemos en cuanta esta nueva información sobre este renderizado que hace Googlebot en la segunda ola de indexación.
Cuándo dije que "Google indexa lo que permanece", era cierto! y ahora sabemos el por qué. Google en una segunda ola, entrará en la url del experimento y obtendrá el HTML, pero renderizará el DOM y ejecutará JavaScript, por lo que cargará el contenido de cada uno de los diferentes escenarios planteados en el experimento, recordamos cuáles eran:
- Carga de contenido tras pasar entre uno y cinco segundos
- Carga de otro contenido tras pasar entre 5 y 10 segundos
- Carga de otro contenido diferente al trasnscurrir al menos 10 segundos).
Una vez renderizado el documento por parte de Googlebot, el contenido que en él haya será el contenido que se indexe, y aquel contenido que no esté, no se indexará.
¿Cómo podemos saber que urls esta renderizando?
Un tema muy importante es saber qué urls está renderizando Google y cada cuánto tiempo lo hace. Esto se convierte en algo crítico para el SEO en aquellas páginas webs basadas en JavaScript, sobretodo si no se realiza un prerenderizado desde el servidor para servir el HTML ya renderizado a Googlebot en la primera ola.
En el SEO para webs en JavaScript conocer a qué contenido es capaz de acceder Google es indispensable para saber si está teniendo problemas a la hora de cargar ese contenido, también para saber cada cuánto renderiza las urls, y cuánto tiempo tarda desde que accede en la primera ola hasta que lo hace en la segunda ya que durante ese intervalo de tiempo Google solo indexará el contenido obtenido sin renderizar durante la primera ola.
Analizando los logs del servidor podemos sacar algunos puntos que se dan en todos los casos;
- Cuando Google accede a la url de origen, lo hace con el campo referer vacío.

- Los recursos cargados desde esa url de origen por parte del navegador, ya sean urls de contenido ajax, hojas de estilo o ficheros js llevan todas en el campo referer la url de origen.

- Los accesos a la url de origen y a las urls o recusos cargados en el renderizado se dan en un pequeño periodo de tiempo, podemos decir casi al 100% que en un periodo de tiempo menor a un minuto.
- El User Agent con el que accede contiene "Googlebot", tanto para la url de origen como para las urls javascript o recursos cargados. Aquí la lista completa de las distintas versiones de Googlebot según su User Agent para hacer las comprobaciones del tipo de Bot
Y de forma menos general, pero que se suele dar cuándo Google renderiza una url
- Google a veces espera el tiempo definido en el setTimeout de JavaScript, pero a veces se salta ese tiempo de espera y ejecuta el javascript casi inmediantemanete.
- No siempre que accede a una url de origen la renderiza, la mayoría de las veces accede a la url pero no hay un renderizado posterior.
- No siempre carga todos los recursos o urls de contenido, a veces carga solo un css, a veces carga todos los recursos, a veces solo una url de contenido... deberemos investigar mejor este comportamiento y saber que no siempre carga todo ni siempre lo mismo.
Ejemplo SQL para saber las urls que Google renderiza
Si tenemos los logs en una base de datos con los siguientes campos, Fecha, path, Status, Referer, User Agent podriamos obtener las urls que han sido renderizadas obteniendo el valor del campo referer de las urls que cumplen estas dos condiciones;
- El User Agent contiene "Googlebot", por supuesto debemos comprobar que realmente sea Google, esto se puede hacer con un reverse DNS.
- El campo referer no está vacío, esto querrá decir que la url de este log ha sido cargada desde la url que aparece en e campo referer. En nuesto caso el valor de este campo es https://www.mecagoenlos.com/Posicionamiento/interpreta-google-el-javascript.php
Representando esto en SQL sería:
SELECT fecha, referer FROM Logs WHERE (UA LIKE '%Googlebot%') AND ((fecha >= '2018-03-01') AND (fecha <= '2018-07-01')) AND (referer != '-') GROUP BY fecha, referer
Y nos devolvería los siguientes resultados, dónde el campo "Referer" es la url de origen, es decir, la url que ha sido renderizada.

Con esto ya podemos saber qué y cuántas urls están siendo renederizadas diariamente por Google, y añadir a nuestro dashboard un dato cada vez más importante.
Además podremos saber qué recursos están dando error 404, que tamaño tienen los recursos descargados y cuánto tiempo tarda Google en descargarlo. Sin duda se puede rascar mucho para merjorar la velocidad de carga y saber cuáles son los recursos que debemos revisar.
Además podremos saber qué recursos están dando error 404, que tamaño tienen los recursos descargados y cuánto tiempo tarda Google en descargarlo. Sin duda se puede rascar mucho para merjorar la velocidad de carga y saber cuáles son los recursos que debemos revisar.
Si quieremos ir un poco más allá y saber cuántas y qué urls están siendo cargadas desde cada url de origen también podemos conocerlo.
Hay un dato que TODAVÍA no he sido capaz de sacar y es cuántas veces ha sido renderizada una url. Este problema me lo planteó Iñaki Huerta, al que también le gustan bastante estos retos. Iñaki ideó un método que podría ser el más cercano al número de cuántas veces al día renderiza Google una url, pero esto ya os lo contará él y muchas más cosas relacionadas en el seoPlus del fin de semana que viene en Alicante.

César Aparicio (@)hace Hace más de 6 años y 273 días
Hola Lino,
Nos conocemos de películas como: Los de Google son muy frikis o Pasodobles y SEO.
Mi cuestión es la siguiente: entiendo que con una función setInterval() en la segunda ola renderice el contenido porque será el mismo pero saltarse el setTImeout () me parece "regular" porque podemos ir invocando cosas diferentes. ¿Qué opinas?
Un placer leerte y, como siempre, gran post.
Lino Uruñuela (@)hace Hace más de 6 años y 273 días
@Cesar saltarse alguna orden del código es un falta de respeto!, que para algo lo hice :D
No se les da muy bien esperar, su tiempo es oro parece... Pero muchas veces sí espera el tiempo del Timeout. Pero pensando que, en tiempo de computación 10 segundos es una burrada, multiplica eso por la cantidad de urls que hay en internet
FDM (@)hace Hace más de 6 años y 273 días
Hola, Lino:
Genial el post, como siempre. Es genial contar con personas tan curiosas y que investigan al detalle el funcionamiento de Google.
Quería lanzarte una pregunta. ¿Cómo se puede ver el onLoad y el onReady? ¿Son eventos que aprecen en la consola de Chrome/Mozilla? Agradecería que me pudieras explicar esto, o bien si lo prefieres escribir un post con este detalle.
Gracias de antemano