Gemini Nano en Google Chrome
Publicado por Lino Uruñuela el 9 de septiembre de 2024
¿Te imaginas poder ejecutar un LLM desde Google Chrome que pueda interactuar con el contenido de cualquier URL que visites? ¡Pues está muy cerca!

Google está habilitando en versiones de prueba de Google Chrome algunas de las funcionalidades que anunciaron el pasado mes de mayo, Built-in AI, y ya está disponible para ser activada. Te recomiendo que solicites unirte al programa de vista previa desde este formulario, ya que podŕás dar feedback directo a los desarrolladores de Google que lo están implementando.
El poder tener un modelo de lenguaje integrado en el navegador web (o en tu servidor) te permite ejecutar un LLM sin necesidad de implementar o administrar tus propios modelos de lenguaje, y esto es un gran avance.
Hoy en día no hay mucha gente ejecutando estos LLM en su propio ordenador, y es normal, porque los requisitos que necesitan para poder ejecutarse son muy elevados, sumado a que la instalación de estos modelos no es siempre tan fácil como parece, y cuando los ejecutas, dependiendo del tamaño del modelo, puedes ir a tomar un café, una paella, dar una vuelta en bici y volver para ver si ha terminado de darte la respuesta :)
Habilitar Gemini Nano en Google Chrome
Lo primero, estas funcionalidades no están todavía disponibles en las versiones "normales" de Google Chrome, sino en las versiones de prueba Google Chrome Dev y Google Chrome Canary, así que realmente no ha llegado todavía, pero sí podemos ir pensando y desarrollando nuevas ideas que tengamos para cuando se habilite para la versión actual de Chrome tenerlo ya listo :)
Pasos para poder usar Gemini Nano en tu navegador:
- Descargar la versión en pruebas de Google Chrome
- Descarga Google Chrome Canary o Google Chrome Dev y confirma que tu versión sea igual o superior a la 129.0.6639.0.
- Debes tener al menos 22 GB de espacio de almacenamiento libre.
- Habilitar Gemini Nano
- Abre chrome://flags/#optimization-guide-on-device-model
Selecciona la opción Enabled BypassPerfRequirement - Abre chrome://flags/#prompt-api-for-gemini-nano
Selecciona Enabled - Cierra y vuelve a abrir Google Chrome
- Abre chrome://flags/#optimization-guide-on-device-model
- Probar si ha sido habilitado correctamente
- Abre la consola del navegador y ejecuta
este comando
await window.ai.assistant.capabilities();
Deberías ver algo así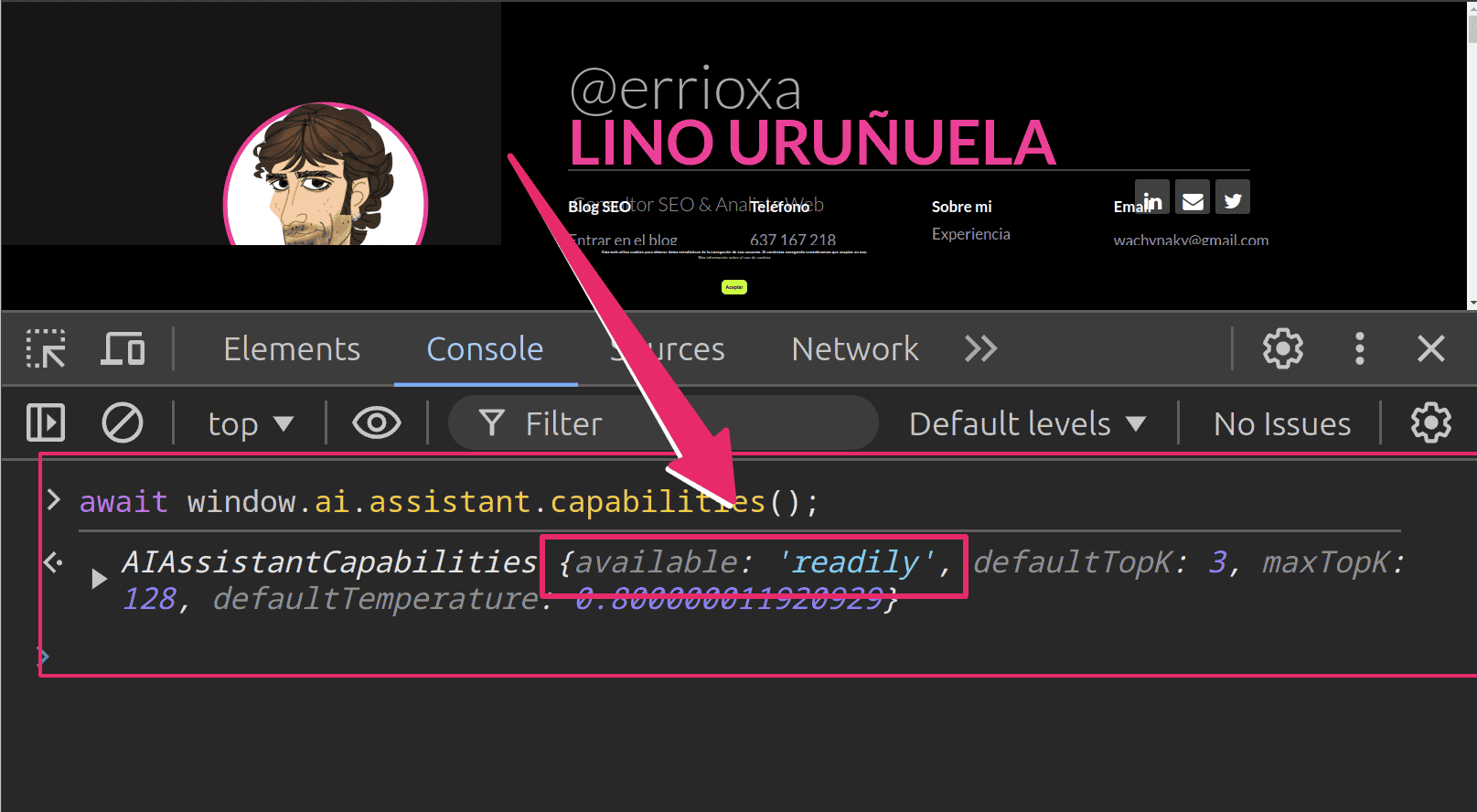
En la rspuesta, si en la variable "available" muestra "after-download" en vez de "readily" es que se está descargando el modelo de Gemini Nano a tu ordenador, podría tardar entre 2 y 5 minutos.
Puedes probar este código, deberías ver la respuesta, que será un maravilloso poema sobre Mecagoenlos.com
const { available, defaultTemperature, defaultTopK, maxTopK } = await ai.assistant.capabilities(); if (available !== "no") { // Crear una nueva sesión con el asistente de AI const session = await ai.assistant.create(); // Pedir al asistente que escriba un poema const result = await session.prompt("Escribe un poema sobre el blog Mecagoenlos.com"); // Mostrar el resultado en la consola console.log(result); }
- Abre la consola del navegador y ejecuta
este comando
Limitaciones de ejecutar Gemini Nano en el navegador
Aunque esta API tiene es capaz de almacenar los últimos tokens en la sesión, el límite por ejecución es menor, concretamente acepta 1.024 tokens de entrada. Supongo que lo irán ampliando, pero de momento esto complica determinadas tareas que podríamos realizar como la que ejecuto en este ejemplo, ya que habría que ir segmentando el texto seleccionado para no solicitar más del límite de tokens de entrada e ir concatenado las salidas.
Gemini Nano en una extensión de Google Chrome
Además de poder ejecutarlo en la consola de desarrollador del navegador también se puede integrar de manera relativamente sencilla como una extensión de Google Chrome. El otro día mostré en Twitter una extensión que estoy creando de prueba y que ejecuta Gemini Nano.
Tampoco podemos esperar que las versiones "Nano", "Mini", etc de los LLMs ofrecerán los mismos resultados que los modelos más grandes, ya que al ejecutarlo en el navegador reamente está usando los recursos que tengas en tu ordenador, y al igual que cuándo ejecutamos los grandes modelos de lenguaje en nuestro ordenador serán necesarios muchos recursos (principalmente Gigas de GPU) para poder cargarse, y tardará bastante más tiempo en devolver la respuesta.
Dicho esto, la velocidad con la que devuelve el resultado en esta primera versión es impresionante, va súper rápido y realmente no se aprecia retardo en las respuestas devueltas.
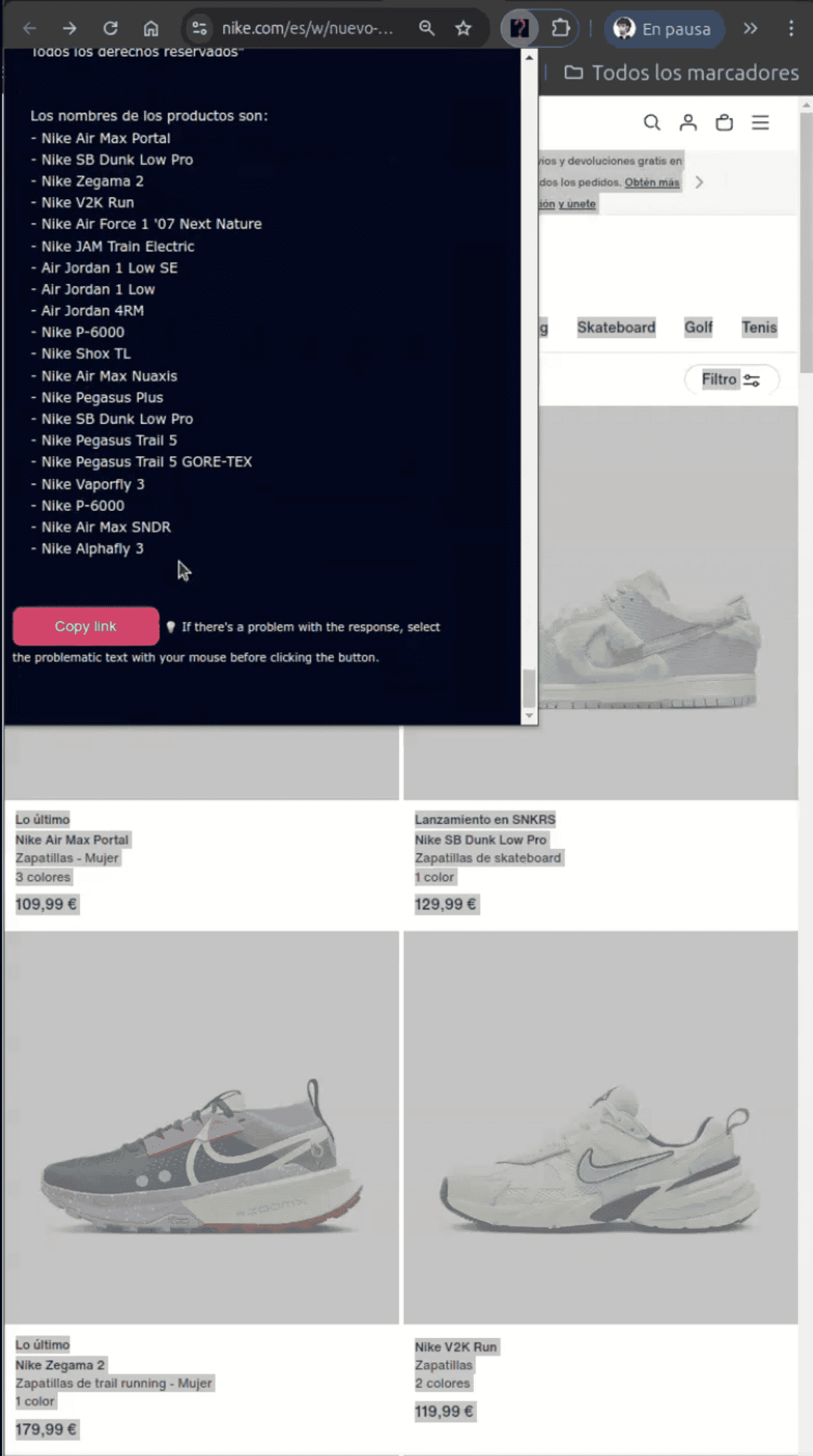
La extensión extrae los nombres de productos que haya cuando el usuario selecciona el texto o parte del texto de una web, Al hacer clic en el icono de la app, se mostrará los diferentes nombres de productos que haya en esa selección.
Imagenes de cómo se ve en una extensión de Google Chrome
[Seleccionamos el texto a procesar]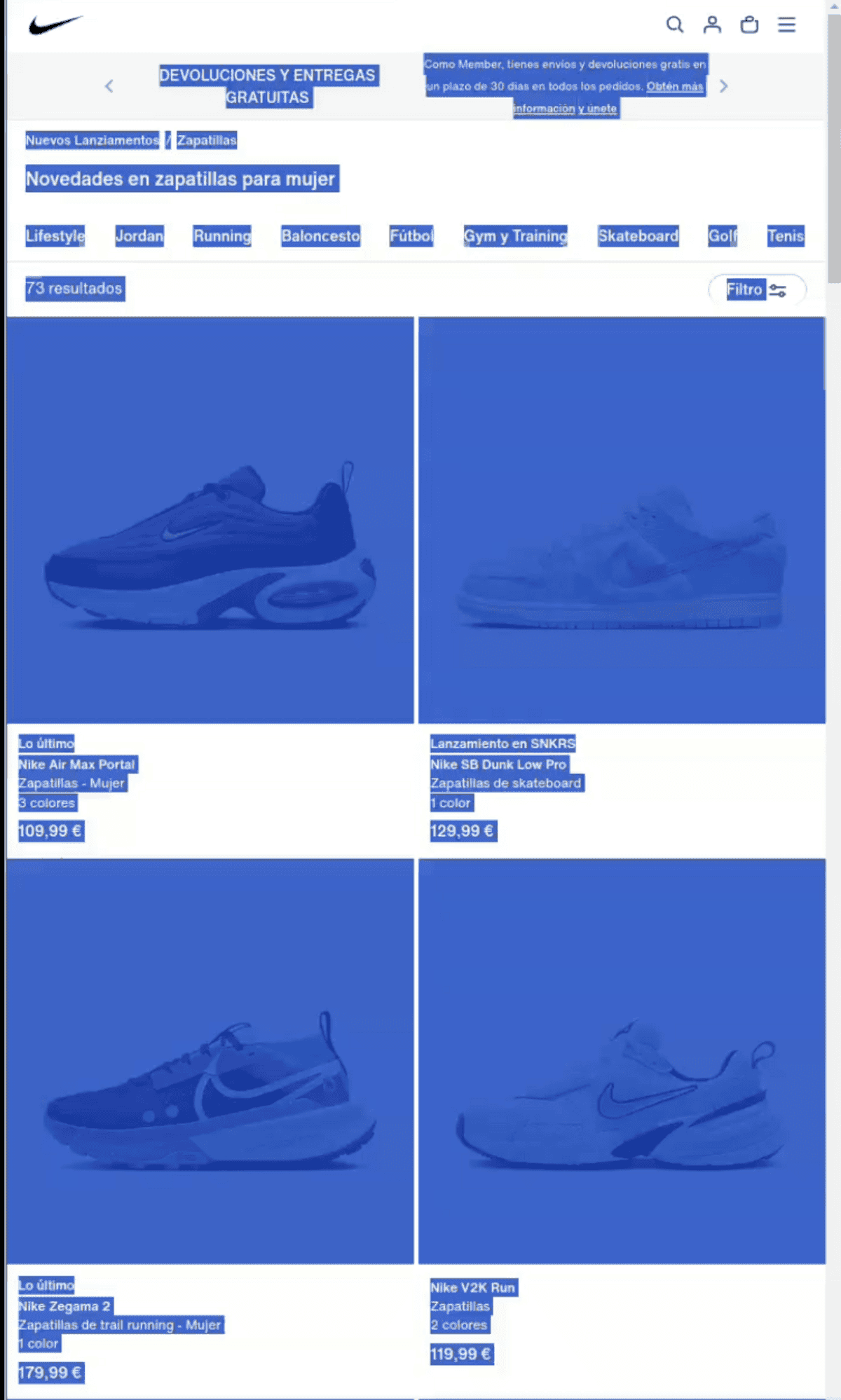
Añado el texto seleccionado al prompt preconfigurado
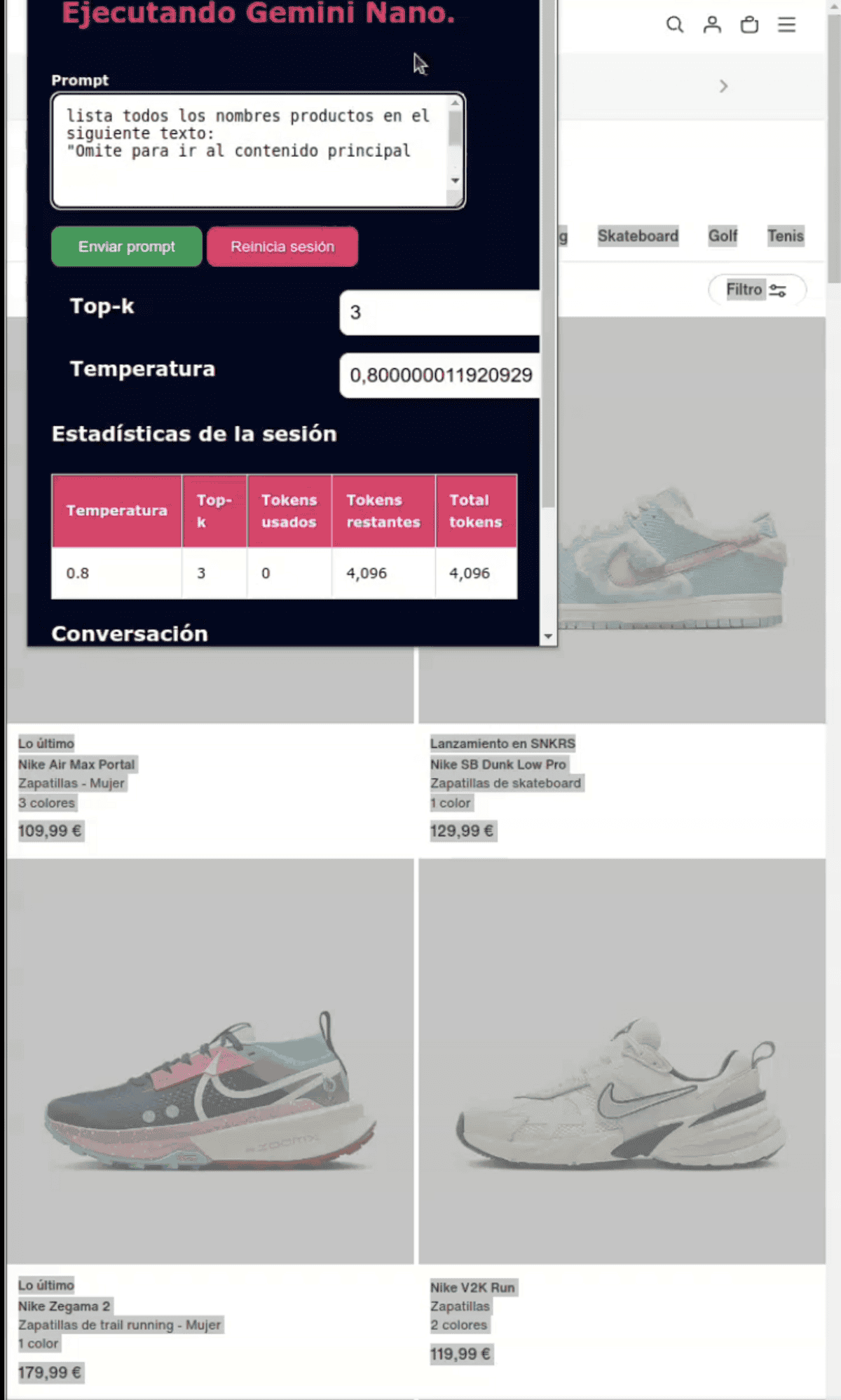
Ejecutamos Gemini Nano para que nos muestre los nombres de cada modelo en el texto

Podemos ver la respuesta en diferentes formatos